
《Efficient Query Processing with Optimistically Compressed Hash Tables & Strings in the USSR》论文笔记
在现代的查询引擎中,许多操作都会使用到 Hash Table,而且由于数据量很大,所以 Hash Table 会占用很多空间,这时 Hash Table 可能就决定了一个查询占用的内存消耗。而且由于 CPU 的缓存层次比较复杂,随机访问时间会根据工作集的大小而呈现数量级的变化。
论文提出了两种减小 Hash Table 的方法:
- 减少填充因子
- 减少 bucket/row 大小
现有的研究基本集中在第一个方法上(比如 Robin Hood Hashing、Cuckoo Hashing、Concise Hash Table),而本篇论文关注第二种方法,即如何减少 bucket/row 大小。论文提出了三种互补的方法:
- Domain-Guided Prefix Suppression:一种轻量级的压缩算法
- Optimistic Splitting:冷热数据分离
- Unique Strings Self-aligned Region (USSR):针对字符串优化
Domain-Guided Prefix Suppression
Domain-Guided Prefix Suppression 的思想是消除比必要的前缀 bits,从而达到减小存储空间的目的
- 如果知道一个值的范围为 [0…1000],那么就可以使用 10 个 bit 来表示一个值
- 可以将多个值"粘"到一起
首先需要找到属性的最大最小值,然后对齐进行规格化。比如一个值的最小值为 -4,最大值为 42,那么可以将每个值减去最小值 -4,比如 10 规格化后为 14。由于最小值与最大值的差值为 46,所以可以使用 6 个 bits 来表示这个属性
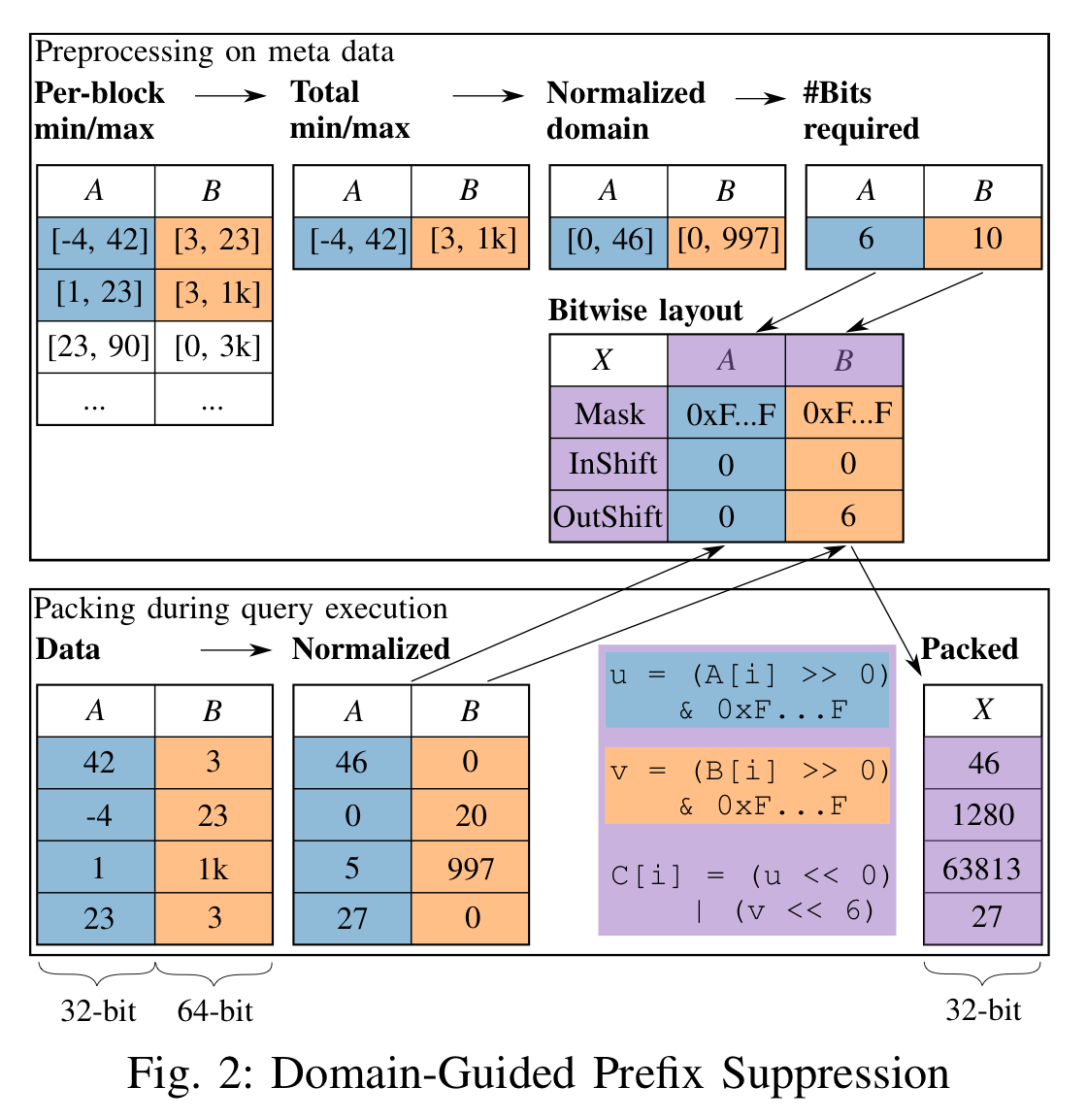
由于一个 int_32 有 32 位可以利用,所以可以将多个属性合并为一个值,一个将 i32 与 i16 合并与解压缩的算法如下:
1 | void pack2_i32_i16_to_i32(i32 *res, int n, i32 *col1, i32 b1, int ishl1, |
由于数据的类型多种多样,可能需要生成很多类似的函数,因此可以使用代码生成技术。
为了提升效率,可以将需要 probe 的 key以同样的压缩方式进行压缩,然后直接进行比较。这样就不需要对 key 进行解压缩了。比如上图中需要查找 B:23,可以将 A:0 与 B:23 进行压缩,然后与 key 的 6~10 bits 进行比较,这可以通过位运算高效地完成
Optimistic Splitting
Optimistic Splitting 将频繁访问的数据存储在 hot area 中,将不频繁访问的数据存储在 cold area 中。这种方法虽然无法减少占用空间,但是可以减少活跃的工作集。
同时将比较大的数据类型转换为小数据类型操作,比如对一个 8 bytes 的数据使用聚合操作 SUM,数据库可能会使用一个 40 字节的 decimal 来进行计算。为了加快计算,可以先使用一个 long 来计算,当数据要溢出时在转换为 decimal 进行计算。这个 long 类型的数据可以看作是热数据,存储在 hot area 中,而 decimal 可以看作是冷数据
USSR
Unique Strings Self-aligned Region (USSR) 中认为在使用 Hash Table 的场景中尽管 key 可能但多,但是不同的 key 可能并没有那么多。所以可以使用一个字符串池来减少字符串的分配。
使用 768kB 来存储 USSR,其中 256kB 为 hash table,512kB 为数据部分。
数据部分划分为若干个定长的 slot,每个 slot 占用 8 bytes,这样就可以划分 64k 个 slot。每个字符串前前的一个 slot 存储这该字符串的 hash 值,因此每个字符串最少占用两个 slot,最多存储 32k 个字符串
hash table 部分每个 bucket 占用 4 bytes,前 2 bytes 存储字符串 hash 的 [16…32] bits 部分,后 2bytes 存储 slot number,用于定位数据部分的数据。当定位数据时,使用 hash 的前 16 为来定位 bucket,然后通过比较 hash 值来判断数据是否相等,如果 hash 值不等,那么就可以直接断定为不相等。
对于插入操作,首先需要判断字符串是否已经存在了,如果已经存在了就不需要再插入了。如果碰到 hash 冲突怎么办,使用线性探测的方法。需要注意的是 USSR 可能拒绝某个插入的值:
- 探测 3 次仍然失败 ➡️ 存入普通的 hash table 中 (这种情况很少,因为装填因子为 0.5( 个 桶, 最多 个数据))
- data Region 满了 ➡️ 存入普通的 hash table 中
USSR 的采用策略是优先插入字符串常量,其次是插入小字符串(最好是字典压缩后的数据)
由于 hash 值是预先计算好的,所以可以快速比较
1 | inline uint64_t hash(char *s) { |

