
W-Tinylfu 学习笔记
已有缓存策略的优缺点:
- LRU:可以很快适应访问模式的改变(热点数据的改变),但是对热点数据的命中率不如 LFU
- LFU:需要维护频次;对于热点数据命中率更高,难以应对突发的稀疏流量,旧数据长期不淘汰,会影响某些场景下的命中率(如外卖),需要额外消耗来记录和更新访问频率
TinyLFU
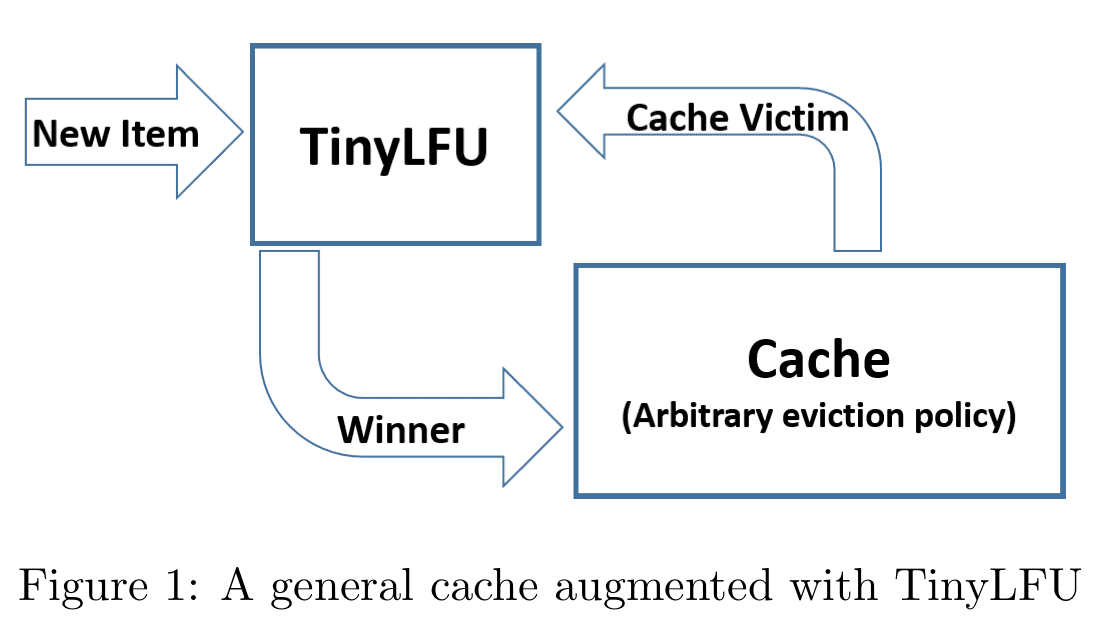
淘汰时策略挑选一个 victim,由 TinyLFU 决定是否使用 new item 替换 victim。
TinyLFU 维护了 Item 最近的统计信息,为了减少消耗,TinyLFU 只使用 sketching 技术进行估算。
两个挑战:
- 刷新机制,只需要最新的历史,需要移除旧 events
- 如何减少内存消耗负载
Approximate Counting
Minimal Increment CBF 是一种计数的 Bloom Filter。支持两个方法:
Estimate:对 key 计算 k 个不同的 hash 值,找到 counter 中相应位置的计数值,返回最小的一个Add:对 key 计算 k 个不同的 hash 值,找到 counte 中相应的位置,只增加最小的计数值
count-Min-Sketch
Estimate:对 key 计算 k 个不同的 hash 值,找到 counter 中相应位置的计数值,返回最小的一个Add:对 key 计算 k 个不同的 hash 值,找到 counte 中相应的位置,增加计数值
sketch counter 的数量与容量相关
Freshness Mechanism
TinyLFU 使用 reset 机制来保证 sketch 中的数据尽可能最新。
每次添加 item 到 sketch 中的时候 increment a counter。一旦这个 counter 达到了 smaple size(W),就将它和所有其他的 counters 的估算值都除以 2
- 不需要额外的空间,只需要 bites
- 增加了高频 items 的精度
由于低频 Item,甚至只出现一次的 Item 占有相当大的比例,如果每次都为这些 item 计算,那么大多数的 counter都需要一个 counter,这样很多只会出现一次 counter 会占用大量的空间。为了减少 counters 的 size,可以使用 Doorkeeper 机制(Bloom Filter)
item 到达时,先检查 item 是否在 Doorkeeper 中,如果不在,插入 Doorkeeper,否则插入 main structures,这样 counter 中就可以不用存储只出现一次的数据了。需要注意的是,每次执行 reset 操作时,需要 clear Doorkeeper(Doorkeeper 中只出现一次的 counter 的频次减半后会变为 0,所以可以 clear Doorkeeper)
有了 Doorkeeper,查找的时候需要修改一下规则:
- 如果 item 在 Doorkeeper 中,估算频率 = TinyLFU 的估算值 + 1
- 如果 item 不在 Doorkeeper 中,返回 TinyLFU 的估算值
估计两个值在 sketch 中的频率,频率高的获胜
W-TinyLFU
由两部分组成:
- main cache,使用 SLRU 和 TinyLFU 准入策略
- window cache 使用 LRU 策略,用于应对 bursts
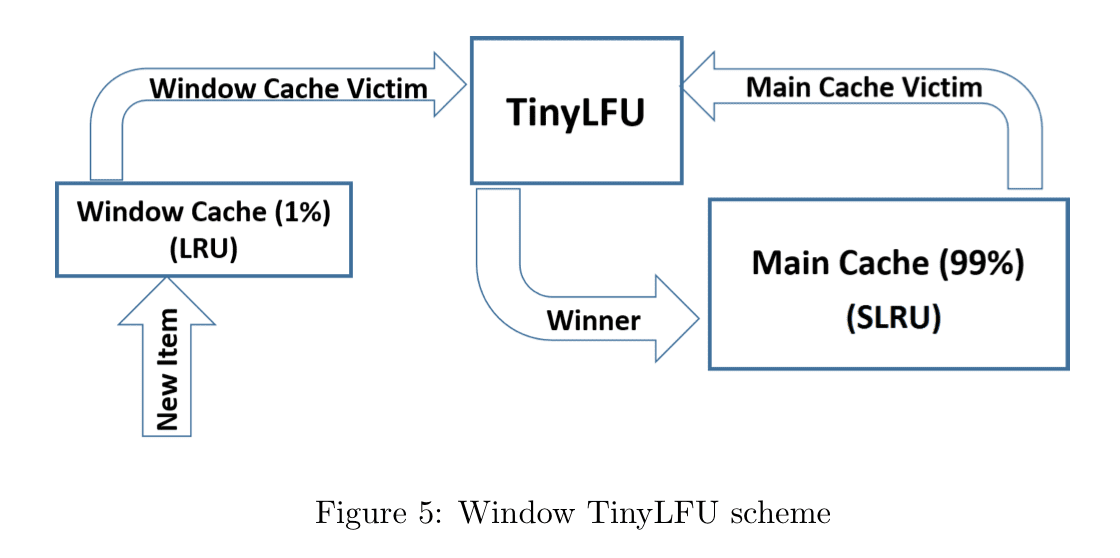
item 总是先进入 window cache,victim 有机会进入 main cache。如果准入,那么 w-TInyLFU 的 victim 成为 victim
参考资料:
- go-tinylfu 一个基于 Go 实现的 TinyLFU
- TinyLFU: A Highly Efficient Cache Admission Policy