
Raft 论文笔记
Raft extended: In Search of an Understandable Consensus Algorithm
Raft 博士论文: Consensus: Bridging Theory and Practice
共识算法的目的通常是为了保持复制状态机的一致性,为了保持复制状态机的一致性,通常采用复制日志的方法,即将保持复制状态机的一致性转换为保持日志的一致性。
Raft 保证的属性:
- Election Safety: 一个 term 最多只能有一个 Leader
- Leader Append-Only: Leader 从来都不会修改或删除 entries,只会向后添加 entry
- Log Matching: 如果两个 log 中的 entry 有相同的 index 和 term,那么该 entry 及之前的所有的 entries 都是等价的
- Leader Completeness:如果一个 entry 被提交了,那么这个 entry 在以后得 term 中也会一直存在
- State Machine Safety: 如果一个 entry 被 apply 了,那么在相同 index,所有其他的 Server 不会 apply 不同的 entry
Leader Election
什么时候触发选举?Leader 会周期性地发送心跳,如果一段时间内 follower 都没接收到 Leader 发送的心跳,就认为 Leader crash 了,就可以发起选举,并推荐自己为 Leader
什么时候可以认为选举成功当大多数 servers 给自己投票是就能成功当选,成为 Leader,并通知 followers,防止 follower 再次发起投票
什么时候可以投票- 在给定 term 没有投过票的(在给定 term 最多投一次票,防止一个 term 出现多个 Leader)
- 日志至少和自己一样新的(保证新 Leader 包含之前 term 提价的所有 entries)
如果在选举期间,candidate 收到 Leader 的请求,那么只要改请求的 term 不比自己小,就承认该 Leader,自己变为 follower
如果candidate瓜分选票,导致选举不出Leader怎么办?随机化选举超时时间
Log Replication
当 leader 接收到一个 command 时,会将其作为一个 entry 加入到本地日志中,然后并行发送请求,要求其他 followers 复制这个 entry。
什么时候可以安全返回当 entry 成功地被复制到大多数 servers 上时,就认为该 entry 被 safely replication 了,就可以将执行结果返回给 client。
成功复制的条件,什么是时候能接受,什么时候该拒绝?两种情况(如何判断?通过 PrevLogIndex 和 PrevLogTerm):
- 日志落后:应该拒绝。
PrevLogIndex处没有 entry,拒绝接受,因为中间有 gap,告诉 Leader 应该从哪里开始发送
- 日志至少与 Leader 一样新:强制接受 Leader 的
- 找到冲突的最开始的地方,删除冲突的 entries,接受 Leader 发送的 entries
- leader: 当 entry 被成功复制到大多数 servers 上时就可以 commit 了
- follower:当 Leader commit 后,自己就可以 commit 了(如何知道 Leader 是否 commit 了?)
- Leader 发送请求时,携带
LeaderCommittedIndex,这样就可以知道可以 commit 到哪儿了
- Leader 发送请求时,携带
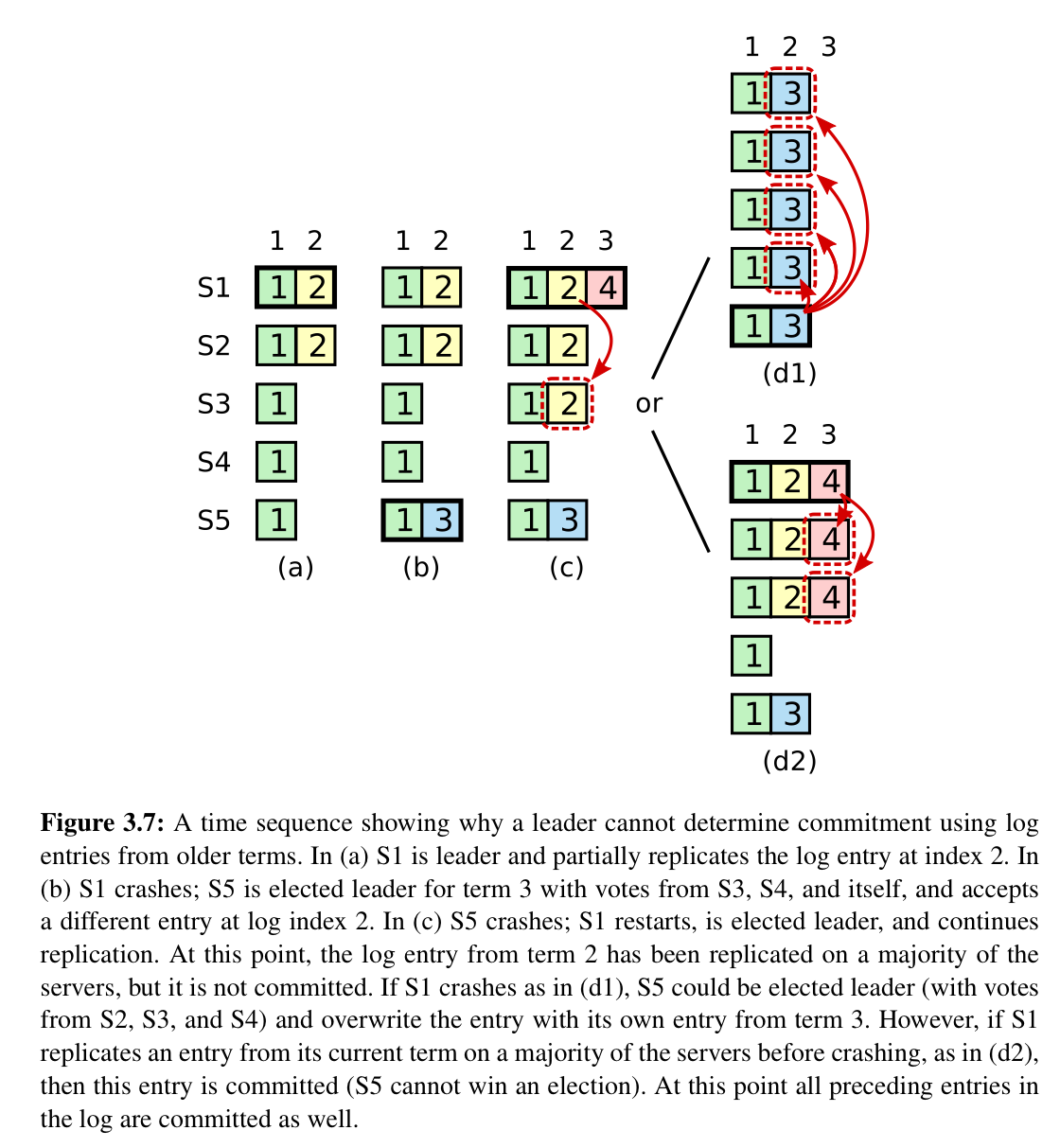
新 Leader 当选时无法快速知道哪些 entries 被提交了。为了保证 Leader Completeness 属性(如果 entry 被提交了,那么最终一定会出现在所有 Server 的 log 中),规定只有当前 term 的 entry 被复制到大多数 Servers 时才能提交,提交时,顺便把之前 term 的 entry 也提交了
- 当前 term entry 被复制到了大多数,那么新 Leader 必定会包含该 entry
- 之前 term 的 entry 被复制到了大多数,只要当前 term 没有 entry 被提交,之前 term 的entry 就不会被提交,所有即使被覆盖也没关系
Log Compaction
随着时间的推移,日志会越来越多,所以需要压缩日志。
快照将当前系统的状态写入稳定存储,然后就可以将这之前的日志丢弃了。
每个 server 都独自地进行快照,即每个 server 的进行快照都与其他 server 无关。为了知道那部分已经写入了快照,还需要记录 lastIncludedIndex 和 lastIncludedTerm。
如果在发送 AppendEntries RPC 时发现 Follower 需要的 entries 已经被写入快照了(即 index < lastIncludedIndex),那么就必须向该 Follower 发送快照。Follower 接受到这个快照会进行接收,并丢弃快照之前的 entries。(如果 Follower 的entries 与快照有冲突,那么丢弃丢弃 follower 的 entries;如果没有冲突,只丢弃快照之前的部分)
哪些数据需要持久化?
currentTerm,防止一个 term 投票多次,以及防止旧 Leader 将新 Leader 的 log 替换了votedFor,防止一个 term 投票多次,以及防止旧 Leader 将新 Leader 的 log 替换了log,防止已提交的 entries 丢失
不需要持久化
-
committed index,重启后可以通过 Leader 的请求快速找到 -
last applied,可以重新 apply RSM,但是如果 RSM 持久化,last applied也必须持久化
Cluster Membership Changes
人工方式:take the entire cluster off-line, update configuration files and restart,会导致集群一段时间不可用,而且如果有人工操作,会增加出错的风险
单步变更
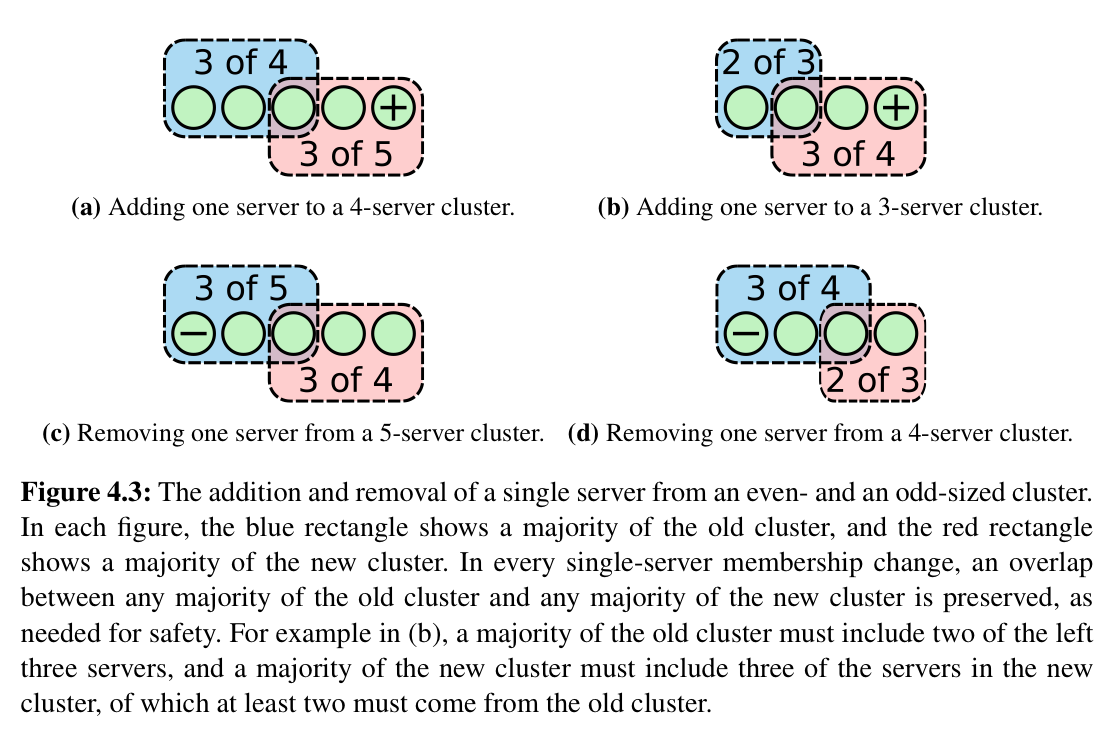
在任一时刻,集群中一次只能添加或者移除一个 server,并且在配置变更的 entry 提交后才能开始下一次变更。
一次只能添加或者移除一个 server 说明新、旧配置中的大多数一定会有重合,那么要想在新、就配置中达成大多数,就都必须得到重合 server 的同意。
如果 Leader 还没成功复制 给大多数就 crash 了,那么 Leader 也不会响应,所以没有关系
如果 Leader 成功复制 给大多数后 crash,那么新当选的 Leader 必然包含
所以,当 server 接收到了新配置,就可以马上使用该配置了
三个问题:
1.新加入的 server 落后很多,导致可用性变差怎么办?
在三个节点的集群中,如果新增一个 server,因为落后很多,server 在一段内不能投票或者参与 commit,导致剩下三个 server 必须全部 work 才能使服务可用。
新加入的节点不参与投票,也不计入大多数中,直到赶上进度
*那么什么时候才能算赶上进度了呢?*目标
- 时间不能太久,因为有可用性问题
- 最好少于 election timeout,因为这是 Client 最少能够忍受不可用的时间
- 尽可能接近 Leader
将追赶划分为若干轮次(rounds),每个 rounds 复制所需要的所有的 entries,下一个轮次就复制这段时间中新添加的 entries。这样随着轮次的增加,需要复制的 entries 就会越来越少。
可以等待一定轮次,
- 如果还没有超过 election timeout,可以将该 server 加入集群
- 如果超过了 election timeout,认为该操作发生错误。调用者需要再次尝试,这样就可以使用更短的时间赶上进度了(因为上次 server 的进度还在)
2.新配置中没有 Leader 怎么办?
两个方法:
- 在变更前进行 Leader transfer,即将 Leader 转移给其他 server,只适用于新、旧配置中有重叠的算法(单步变更和新旧配置有交集的联合变更)
- 变更完成后( 提交后),主动移除自己并 step down
- 必须在 提交前移除
- 在 提交前,该 server 也能够发起选举
3.被移除的 server 发起选举扰乱集群怎么办?
两个手段:
Pre-Vote,发起选举前,检查自己能否成为 Leader。不能杜绝,但是能够有效减少这种情况- 租约,在 election timeout 之前,如果接收到了有效的心跳,就认为该 Leader 还在,不接受选举
Joint Consensus
two-phase approach,引入一个过度阶段,新旧配置同事存在,
- Log entries 同时复制到新、旧配置的所有 Server 中
- 新、旧配置中的 Server 都有可能成为 Leader
- 共识要求同时在新、旧配置中达成,即既是新配置中的大多数,有是老配置中的大多数
具体操作:
- Leader 将配置变更请求封装成 entry(),发送给新配置和老配置中的所有 servers
- 一旦 servers 接收到了配置变更的 entry,就开始使用 这个配置(即便还没有提交)
- 提交后,创建一个新 entry(),发送给集群中的 servers
- 一旦 servers 接收到了配置变更的 entry,就开始使用 这个配置(即便还没有提交)
- 提交后,就可以关闭不在集群中的 servers 了
三个问题(类似于单步配置变更)
- 新加入集群的 Server 落后太多,需要花很多时间才能追上 --> 使之成为 leaner,不参与投票,直到追上进度
- 旧集群的 Leader 可能不在新集群中 --> Leader 在 提交后 主动下台成为 follower,下台期间不参与 majority
- 被移除的 servers 可能会扰乱集群,比如收不到心跳包,发起选举 --> 租约,如果 server 认为 Leader 存在,就不投票; Pre-Vote
Client Interaction
线性一致性:
- 为每个 Client 设置一个唯一标识符
- 为每个 Command 设置一个唯一的序列号
- state machine 跟踪每个 Client 处理过的序列号
只读请求可以不用写入 log,但是如果没有额外的机制会增加读取过期数据的风险,因为 Leader 可能已经不是 Leader 了,但是它还不知道。比如网络分区,Leader 被分到了少数的那个分区,这样就会出现两个 Leader。如果从旧 Leader 中读取,就会读取到过期数据
Leader 如何知道自己是否还是 Leader 呢?
Leader 可以与集群中的 server 交换心跳,如果收到大多数的回复(同意),就说明自己还是 Leader,于是可以回复 Client
由于 Leader 一定有所有已经提交的 entries,但是刚刚当选的 Leader 还不知道 commit index,所有一个发送一个 no-op entry 来快速知道自己的 commit index
优化
Leader Transfer
使用场景:
- Leader 必须 step down,比如需要关机、重启
- 其他 server 更适合当 Leader,比如考虑负载、或者最小化延迟
- Leader 停止接收 Client request
- Leader 将 entries 发送给 target,使其 log 与自己匹配
- 发送
TimeoutNow请求,要求 target 马上开始选举
- 一个 election timeout 没有完成,认为失败,Leader 重新开始接受 request
- 如果成功,Leader 会接收到心跳,从而 step down
PreVote
网络分区后重新加入集群,可能会造成惊群效应
在投票前,新增一个预选举阶段,只有当大多数 server 能够投票时,才发起选举。预投票不增加 term
能够投票是指:
- 日志足够新
- 一定时间内没有收到 Leader 心跳
只读查询优化
Read Index
- Leader 保存当前的 commit index,作为
ReadIndex - Leader 确保自己仍是 Leader(发送心跳)
- 等待 RSM advance 到
ReadIndex - 回复 Client 从 RSM 中得到的查询结果
发送心跳会产生延迟,可以利用租约(Lease)机制降低延迟,即如果一段时间(election timeout) Leader 发送的心跳被大多数接受了,那么就认为自己仍是 Leader。但是租约依赖于时钟,会增加读取过期数据的风险
可以让 follower 也参与读取,但是会增加读到过期数据的风险。可以让 follower 向 Leader 发送请求询问 ReadIndex,然后等待自己提交大 ReadIndex。
Client 可以携带序列号,如果 Client 携带的序列号是 n,那么 server 至少需要等到 n 被提交