
从状态机的角度理解 ACID
声明:以下内容都是我 xjb 写的,不保证其正确性
引言
不知道是谁说的,程序就是状态机。所谓状态机,就是一种数学计算模型。对于给定的输入,状态机会从一种状态变为另一种状态。同时,在任意时刻,状态机只能处于有限状态中的一种。
下面我们将从状态机的视角重新解释事务的 ACID。
以下内容纯属我 xjb 乱想的,不要太当真
ACID
ACID 是事务的四种特性,其解释如下:
- Atomicity 原子性:一组操作要么全部完成,要么全部失败。不存在部分成功部分失败的情况
- Consistency 一致性:如果事务开始前,DB 的状态是一致的,那么事务结束后,DB 同样是一致的
- Isolation 隔离性:不同事物之间应该相互隔离,不应该互相影响
- Durability 持久性:事务对数据做出的修改因该能够持久化都非易失性存储设备上
原子性
首先我们从状态机的视角理解原子性,其状态变化图大概如下图所示
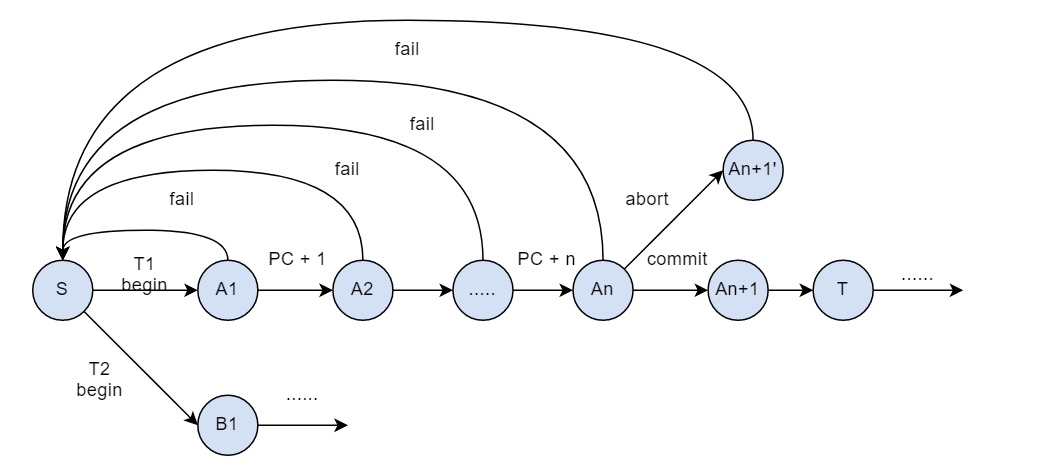
在上图中,数据库处于状态 S,当事务 T1 使用 Begin 表示开启一个事务时,数据库从状态 S 转变为状态 A1,在事务中,没执行一个命令,都会让数据库的状态发生改变,假设其状态改变由 A1 到 A2 一直到 An。假设 An 是事务的最后一步操作,如果用户觉得没有问题了,可以使用 Commit 将事务提交,此时数据库会变为状态 An+1,这是事务成功完成了,即事务中的所有操作全部成功了。
但是如果在事务的任何一个状态发生故障或者在最后使用了 Abort 操作,都会将事务重新变为状态 S(起始状态)。也就是说,在事务的执行过程中,只要有一个操作失败,所有操作都会失败。这就是事务原子性。
如何实现原子性呢?从状态转换图中,我们发现,如果事务成功,我们什么都不需要做,直接往下执行就好了。但是一旦事务失败了,我们就需要将状态改变为初始状态。所以一种直观的想法是记录下事务起始的状态,事务失败后,我们直接回滚到这个状态。我们有两种方法可以实现这种想法
第一种是使用 Shadow Paging 技术,在操作数据时,我们将数据复制一份,然后我们在这个副本上进行操作,如果事务提交,我们将这个副本作为数据库的最终状态,如果事务回滚了,我们丢弃这个副本,继续使用原来的数据库状态。
第二种方法是使用日志记录下我们做出的操作,即在执行操作前,我们先记录下此时的做出的操作,然后再执行。如果执行成功,我们继续执行就行了。如果发生错误,需要回滚时,我们通过日志向前回放,就可以达到数据库的初始状态了。这种在操作先先记录日志的方法叫做 Write-Ahead Log,简称 WAL。
一致性
假设在起始状态 S 数据库在某个规则下处于一致状态,并且事务执行结束后,在相同规则下也处于一致性状态,那么一致性就得到了满足。即一致性状态 A —> 一致性状态 B
隔离性
在上面的状态图中,我们发现,状态 S 接收 T1 的 begin 会进入状态 A1,接收 T2 的 begin 会进入状态 B1,也就是说,事务是并发执行的。我们希望一个事务对数据做出的改变不会影响其他事务,即事务可以从状态 A1 一直到 状态 An,不会收到其他事务的影响,这就叫做事务的隔离性。
一般认为事务的隔离性有四种
- 读未提交:一个事务可以读到未提交事务所处的修改,其状态状态转换图如下所示(有些状态并没有画出,比如 Bn abort)

假设 T1,T2 使用两条线程,分别开启了两个事务,并且交错执行。在任意时刻,事务 T1 可以看到事务 T2 做出的修改,比如 A2 状态是 T1 事务在 B1 状态的基础上转化而来的。这就是未提交读。
不难看出,未提交读有很大的问题。比如在 Bn 状态,事务 T1 执行操作后到达 An 状态,然后进行了回滚。但是事务 T2 此时进行了提交,将数据持久化了。此时提交后的状态 T2 是我们想要的正确状态吗?不是,因为 Bn 状态的由来实在 A1,A2… 的基础上的到的,但是 T1 将这些状态回滚了,也就是说 T2 读写了脏数据。
- 读已提交:一个事务只能够读取到其他事务提交的事务,其状态转换图如下所示:

事务 T2 由于不能看到 T1 做出的修改,即看不到 A1,A2 状态,只能看到 S 状态,所以只能由 S 状态变为 B1 状态。这样事务就不会读写一个未提交事务修改的数据了。
但是程序是状态机,在任意时刻只能有处于一个状态中的一种,在 T2 begin 时,程序到底处于状态 S 还是状态 A2 呢?这是不是不符合状态机的规则呢?
不知道你有没有想到 fork,当程序执行 fork 时,会创建一个子进程,这个子进程拥有和父进程一样的地址空间,也就是说拥有一样的状态机模型。如果 T1 begin 时 进行了 fork,那么 T1 对状态的变换是在子进程的基础上进行的,不会影响父进程的状态。同样 T2 begin 是也是对另外一个子进程的基础上进行的,所以才会出现上图的状态机。(S, S1, S2 表示数据库的真正状态,Ai, Bi 表示子进程的状态)
看到这里,你是不是对如何实现读已提交有一点想法了?没错,还是使用 Shadow Paging,将要读写的数据复制一份。当有事务提交时,通知其他事务读取提交事务做出的修改。不过在实现上不仅需要空间的开销,还需要使用额外的通知机制,未免有些麻烦,所以我们需要另辟蹊径。
MySQL 中通过 MVVC + 2PL 的机制可以实现可提交读。在执行每一个 SQL 语句时,它会读取当前视图版本,因为有 2PL 的存在,如果其他事务正在修改数据,事务会阻塞,从而实现读已提交。
于是我们想到使用锁,事务提交前,我们将数据锁住,事务提交后,我们才能看到事务做出的修改。为了提高并发度,我们做出这样的限制:
- 读取数据时加读锁,读取完成后释放
- 写数据时加写锁,事务提交时才释放

在 A=0, B=1, WLock(B) 这个状态时,T2 开始事务,因为 T2 不需要写 B,所以不会获取 B 的锁,也不会阻塞。T2 获取 A 的锁,然后写了 A,释放锁后提交。在提交期间,T1 无法修改或者读取 A,因为无法获取到 A 的锁,也就无法读取到事务 T2 做出的修改了。只有等到 T2 提交释放锁后,T1 才能继续修改 A。
但是读已提交也有问题,比如在 T2 事务提交后,如果 T1 读取了 A,那么会造成在一个事务中前后两次读取同一个数据出现了两种不同的值。
- 可重复读:在一个事务的前后两次查询中,必须保证结果是一致的
在上面提到的 Shadow Paging 的方法就可以实现可重复读,而且我们无需通知其他事务读取最新的数据。

这样是不是太简单了?如果 T1 将数据 a 自增了 1,T2 也将 A 自增了 1,那么最终结果会得到 a=1。所以这是有问题的。那么怎么办呢?在提交时我们需要校验是否有冲突,如果有冲突,我们就不能提交,应该回滚。具体实现可以参考基于时间戳的并发控制。修改后的状态转换图如下图所示

在有些场景中,我们可能不能忍受这么多的回滚,所以我们可以选择从最新的状态重新开始执行事务,也可以使用锁来控制并发。使用锁的并发要求如下:
- 读数据时加读锁
- 写数据时加写锁
- 事务提交时才释放锁
关于锁的状态图我就不画了,大家可以自己思考一下(其实和之前画的读已提交的差不多)
- 可串行化:事务的执行效果和事务串行执行的效果相同
这个实现就很简单了,状态转换图类似 A–>B–>C 这样,我就不画图了
持久性
持久性要求事务能够持久化到磁盘中,其状态装欢相当于从一个不安全的状态转换为了一个安全的状态,类似于 A–>A’,所以我也不画图了,理解了就行。



