引言
LevelDB 是个基于 LSM 结构的 KV 数据库,其写入涉及到 Memtable、SSTable、Log 等多个组件。本文将会简要介绍一下 LevelDB 写入一个 Key/Value 的流程。
WriteBatch
无论是 PUT 操作还是 DEL 操作,底层都会调用方法向 WriteBatch 中写入,WriteBatch 可以批量向数据库中写入数据。
1 2 3 4 5 6 7 TEST (WriteBatchTest, Multiple) { WriteBatch batch; batch.Put (Slice ("foo" ), Slice ("bar" )); batch.Delete (Slice ("box" )); batch.Put (Slice ("baz" ), Slice ("boo" )); WriteBatchInternal::SetSequence (&batch, 100 ); }
随后批量写入数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 Status DBImpl::Write (const WriteOptions& options, WriteBatch* updates) { Status status = MakeRoomForWrite (updates == nullptr ); uint64_t last_sequence = versions_->LastSequence (); Writer* last_writer = &w; if (status.ok () && updates != nullptr ) { WriteBatch* write_batch = BuildBatchGroup (&last_writer); WriteBatchInternal::SetSequence (write_batch, last_sequence + 1 ); last_sequence += WriteBatchInternal::Count (write_batch); { mutex_.Unlock (); status = log_->AddRecord (WriteBatchInternal::Contents (write_batch)); bool sync_error = false ; if (status.ok () && options.sync) { status = logfile_->Sync (); } if (status.ok ()) { status = WriteBatchInternal::InsertInto (write_batch, mem_); } mutex_.Lock (); } versions_->SetLastSequence (last_sequence); } return status; }
MemTable
无论如何,写入操作最终都会调用 memtable.Add 方法进行插入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void MemTable::Add (SequenceNumber s, ValueType type, const Slice& key, const Slice& value) size_t key_size = key.size (); size_t val_size = value.size (); size_t internal_key_size = key_size + 8 ; const size_t encoded_len = VarintLength (internal_key_size) + internal_key_size + VarintLength (val_size) + val_size; char * buf = arena_.Allocate (encoded_len); char * p = EncodeVarint32 (buf, internal_key_size); std::memcpy (p, key.data (), key_size); p += key_size; EncodeFixed64 (p, (s << 8 ) | type); p += 8 ; p = EncodeVarint32 (p, val_size); std::memcpy (p, value.data (), val_size); assert (p + val_size == buf + encoded_len); table_.Insert (buf); }
首先,leveldb 采用 varint 编码写入要编码值得长度,其大致思路是将一个字节中的低 7 位用来写入数据,剩下的高 1 位用来表示是否结束。比如一个大小为 127 的数据经过编码后得到 0111 1111;大小为 128 的数据经过编码得到 00000001 11111111。
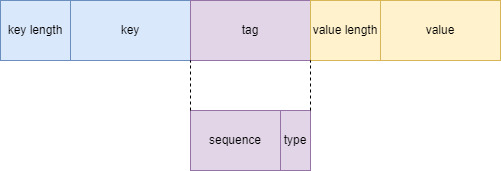
从代码中可以看出,leveldb 是将 key/value 作为一个 key 插入底层的数据结构(跳表)中的,这也就意味着跳表中只存储了 key,但是这个 key 中存储着我们想要存储的 key/value 数据。key 的格式如下图所示
key length 表示 internal_key 的长度。internal_key 包括途中的 key 和 tag 部分
key 表示插入 key 的内容
tag 包含两部分。高 7 个字节表示序列号,低一个字节表示 type。leveldb 有一个全局的序列号,每插入一个 key/value 序列号就会自增 1,可以用来区别同一个 key 的版本。type 表示添加数据的类型,是插入新数据,还是删除数据
value length 表示 value 的长度
value 表示 value 的内容
SSTable
由于内存有限,所以我们需要一种机制,将内存中的数据写入磁盘。在经典的 LSM 树中,当 MemTable 达到一定阈值时,会将 MemTable 中的内容写入到磁盘中。LevelDB 在 MemTable 达到一定阈值后,会先将 MemTable 变为 Immutable MemTable,从名字就可以看出,这个 MemTable 是不可变的,也就是只读的,查询的时候仍然可以在这个 MemTable 中查找,只是不再接受写入操作了。后台会有一个线程,定期将 Immutable MemTable 写入到 sst 文件中。
在写入 MemTable 前,会先检查 MemTable 是否达到了阈值,如果达到了阈值,就将 MemTable 标记为不可变,然后创建一个新的 MemTable 用于写入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 Status DBImpl::MakeRoomForWrite (bool force) { while (true ) { if (allow_delay && versions_->NumLevelFiles (0 ) >= config::kL0_SlowdownWritesTrigger) { } else if (!force && (mem_->ApproximateMemoryUsage () <= options_.write_buffer_size)) { break ; } else if (imm_ != nullptr ) { background_work_finished_signal_.Wait (); } else if (versions_->NumLevelFiles (0 ) >= config::kL0_StopWritesTrigger) { background_work_finished_signal_.Wait (); } else { uint64_t new_log_number = versions_->NewFileNumber (); WritableFile* lfile = nullptr ; s = env_->NewWritableFile (LogFileName (dbname_, new_log_number), &lfile); if (!s.ok ()) { versions_->ReuseFileNumber (new_log_number); break ; } delete log_; delete logfile_; logfile_ = lfile; logfile_number_ = new_log_number; log_ = new log::Writer (lfile); imm_ = mem_; has_imm_.store (true , std::memory_order_release); mem_ = new MemTable (internal_comparator_); mem_->Ref (); MaybeScheduleCompaction (); } } return s; }
从上面的代码中可以看到,当 MemTable 达到阈值时,会变为 Immutable MemTable,然后创建一个新的 MemTable 用于写入。同时,还会删除 wal 文件并创建一个新的 wal 文件。wal 文件是预写日志,用于恢复内存中的数据,因为
最后,会调用 MaybeScheduleCompaction 触发后台线程的调度,后台线程会将 Immutable MemTable 写入 sst 文件。后台线程最终会调用 WriteLevel0Table 写入 sst。
WriteLevel0Table 中会先将 Immutable MemTable 中的数据写入一个 builder 中,这个 builder 对上层屏蔽了细节,我们只需要传入一个迭代器,他就会帮我们遍历数据,写入 sst。这一部分待会儿研究 sst 文件格式的时候再介绍。
写入 sst 文件后,我们要将 sst 写入那一层呢?经典的实现是写入第 0 层,但是 LevelDB 对其做了一点小优化。他会从第 0 层开始判断要写入的 sst 是否与该层已有的 sst 文件有重叠,如果没有重叠,寻找下一层,直到找到最后一个没有重叠的层。具体逻辑在 PickLevelForMemTableOutput 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int Version::PickLevelForMemTableOutput (const Slice& smallest_user_key, const Slice& largest_user_key) int level = 0 ; if (!OverlapInLevel (0 , &smallest_user_key, &largest_user_key)) { InternalKey start (smallest_user_key, kMaxSequenceNumber, kValueTypeForSeek) ; InternalKey limit (largest_user_key, 0 , static_cast <ValueType>(0 )) ; std::vector<FileMetaData*> overlaps; while (level < config::kMaxMemCompactLevel) { if (OverlapInLevel (level + 1 , &smallest_user_key, &largest_user_key)) { break ; } if (level + 2 < config::kNumLevels) { GetOverlappingInputs (level + 2 , &start, &limit, &overlaps); const int64_t sum = TotalFileSize (overlaps); if (sum > MaxGrandParentOverlapBytes (vset_->options_)) { break ; } } level++; } } return level; }
找到从 0 开始的最后一个没有重叠的 level 后,我们可以直接将 sst 文件写入该层。LevelDB 对这个 level 做了一点限制,不能超过 config::kMaxMemCompactLevel 的大小(默认为 2)。
下面我们来介绍一下 builder 的流程
builder 会利用传入的迭代器遍历集合的数据,然后加入 builder。builder 是以 block为单位写的,当 block 写满后,会写回 sst 文件中,然后继续写入一个新 block。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void BlockBuilder::Add (const Slice& key, const Slice& value) Slice last_key_piece (last_key_) ; size_t shared = 0 ; if (counter_ < options_->block_restart_interval) { const size_t min_length = std::min (last_key_piece.size (), key.size ()); while ((shared < min_length) && (last_key_piece[shared] == key[shared])) { shared++; } } else { restarts_.push_back (buffer_.size ()); counter_ = 0 ; } const size_t non_shared = key.size () - shared; PutVarint32 (&buffer_, shared); PutVarint32 (&buffer_, non_shared); PutVarint32 (&buffer_, value.size ()); buffer_.append (key.data () + shared, non_shared); buffer_.append (value.data (), value.size ()); last_key_.resize (shared); last_key_.append (key.data () + shared, non_shared); counter_++; }
从代码中可以看出,一条 key/value 数据在 block 的存储形式如下图所示:
同时,在 block 中,每隔 block_restart_interval 个 key 会记录一个 restart 点,用于记录 base key。在 restart 点后的 key 都只需要存储与 base key 不同的部分即可。也就是说 key 的存储采用了前缀压缩的思想。比如 base key 为 apple,存储 application 时就只需要存储 ication 即可。但是为了能够恢复 key,我们还需要存储与 base key 相同部分的长度
当 block 写满时会写回磁盘中的 sst 文件中
1 2 3 4 const size_t estimated_block_size = r->data_block.CurrentSizeEstimate ();if (estimated_block_size >= r->options.block_size) { Flush (); }
1 2 3 4 5 6 7 8 9 Slice BlockBuilder::Finish () { for (size_t i = 0 ; i < restarts_.size (); i++) { PutFixed32 (&buffer_, restarts_[i]); } PutFixed32 (&buffer_, restarts_.size ()); finished_ = true ; return Slice (buffer_); }
在 block 中除了上面记录的 kv 之外,还需要将 restarts 记录进去。最后还会添加 restarts 数组的长度,然后调用 WriteRawBlock 写入 crc 校验码,然后刷回磁盘。由于这个 block 是写数据的,所以叫做 data block,sstable 中还有很多其他的 block。一个 data block 的格式如下图所示:
除了 data block 外,sstable 中还有一些 meta block,其中包括 meta index block,里面记录了 data block 的 offset,最大 key 和大小。如果有布隆过滤器的话,还会有一个 block 用于存放布隆过滤器的数据