
15-445 MVCC
15-445 地址 https://15445.courses.cs.cmu.edu/fall2021/schedule.html
MVCC 的基本思想就是写操作不阻塞读操作,读操作也不阻塞写操作。要做到这一点,我们基本上就不能加锁了。在 MVCC 中会为每个事务创建一个一致性快照,事务都是在这个快照上进行操作的。
实现原理
MVCC 为每个事务分配了一个时间戳,并根据时间戳来决定是否能够访问某个数据的历史版本。以下图的例子,我们来分析一下 MVCC 的执行流程。
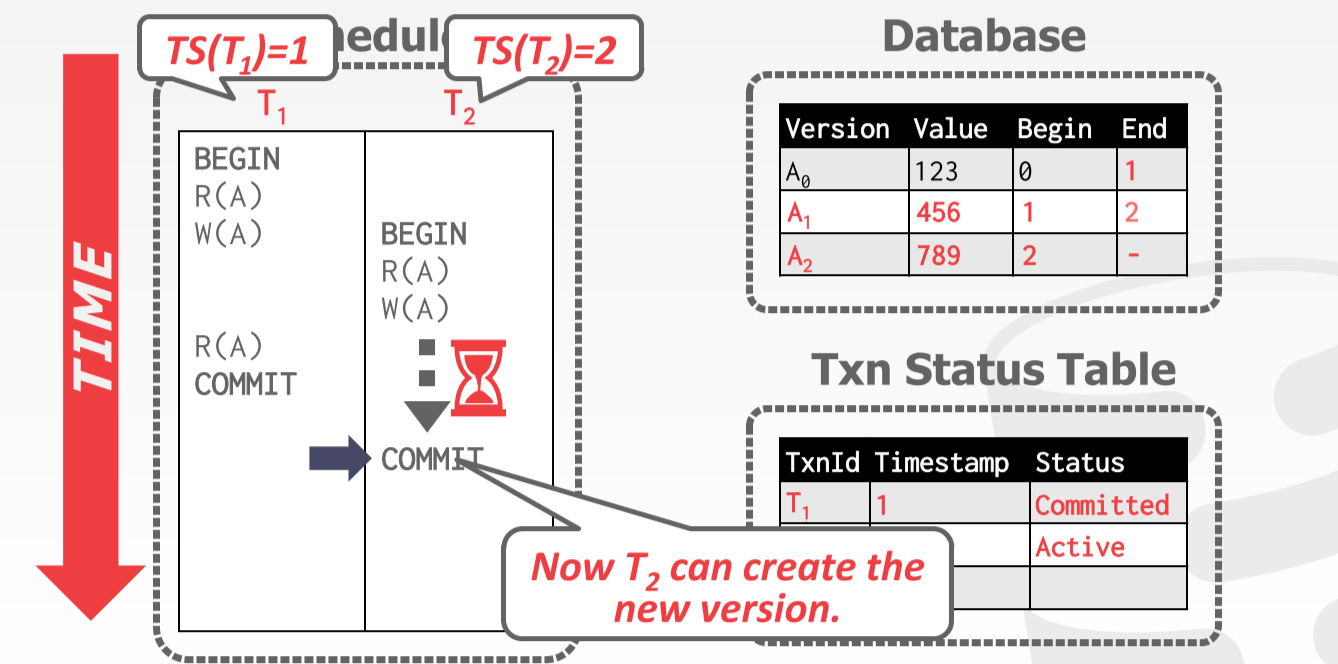
的时间戳为 1, 的时间戳为 2。 先开始事务,并读取 A,这时它读取的版本是 。然后 对 A 进行写操作,会创建一个新版本的数据 。并将老版本 的结束时间戳设置为 1,表明在时间戳 0~1 内,该版本数据有效。
接着 开启了事务,并读取 A,那么这是它应该读取哪个版本的数据呢?在这里,它应该读取 版本的数据,因为 还没有提交。如果我们读取了还没有提交的事务的话就有可能造成脏读,如果 在 提交前回滚了,那么必须面临级联回滚的问题。如果 在 提交后回滚,那么数据就会出错。 所以我们不能读取还没有提交的事务的版本。接着 写 A,那么这时 应该写哪个版本的数据呢?
应该写 版本的数据。 必须写新版本的数据,否则就有可能会出错。假设 给 A 加了 1, 也是给 A 加了 1,如果 , 均提交成功,那么最后得到的结果是 A + 1,这就会出错。所以这是必须读取新版本的数据,即 必须等待 提交后才能写。接着 读取 版本的数据,然后提交。现在 终于可以开始写 A 了,它并不会直接写 ,而是创建一个新版本 。操作完成后 就可以提交了。
在 MySQL 中,MVCC 的实现也是这样。在事务开始时,会创建一个一致性快照,事务的读取操作都会读取这个快照。但是当执行写操作时,它必须读取最新的数据。
从上面的流程中我们可以看到,单独的 MVCC 并不能实现 Serializable(比如 的写操作),必须借助其他并发控制协议(如 T/O、OCC、2PL)才能够达到 Serializable。
实现方式
DBMS 通过维护一个版本链来实现 MVCC,当事务读写事务时,可以沿着版本链找到对应的可见的版本。下面我们来讨论一下 MVCC 的实现方式。
Append-Only Storage
在 Append-Only Storage 方案中,将新版本数据与旧版本数据存储在一张表中,每次数据更新就在表中添加一条新 tuple。不同版本之间通过一个指针连接,这样沿着指针就可以找到不同版本的数据了。
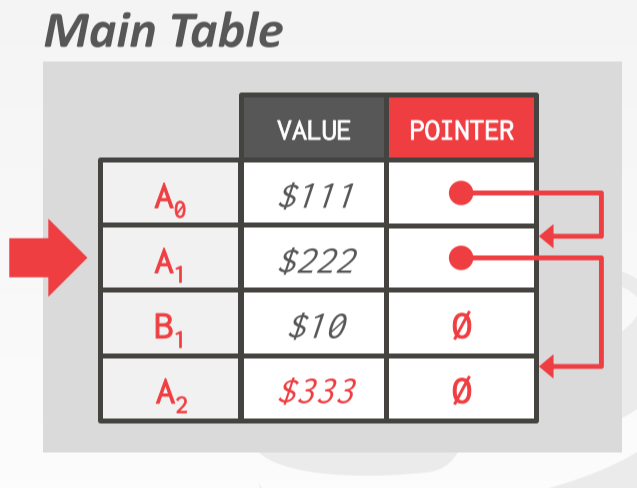
我们可以将新版本插入到链表的末尾,但是每次查找时必须遍历整个链表。我们也可以将新版本插入到链表头,但是每次更新时必须更新所有版本的指针引用。所以这就体现了 trade-off
Time-Travel Storage
在 Time-Travel Storage 方案中,将新旧版本的数据分开存储。在 Main 表中只存储最新版本的数据,在 Time-Travel 表中存储老版本的数据。新版本数据总有一个指针,指向老版本数据的头节点。
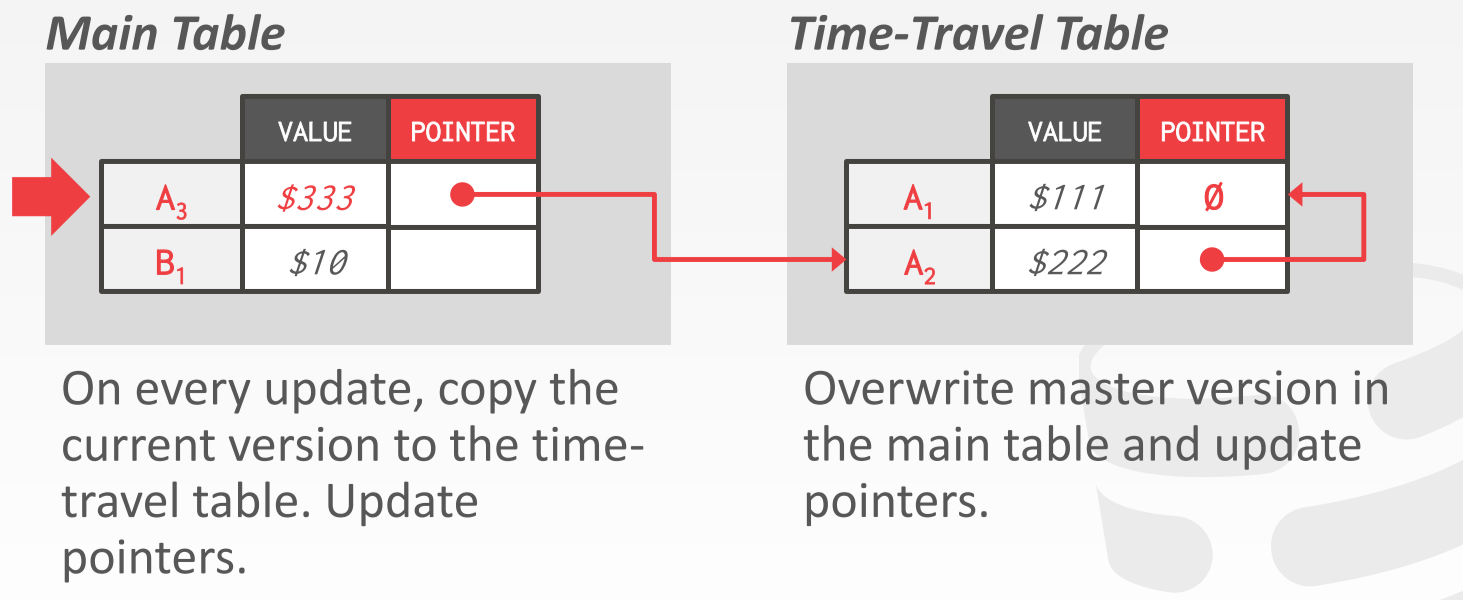
每次数据更新时,主表会将当前版本的数据复制到 Time-Travel 表中。完成之后,Main 表就可以更新数据了,同时还会更新到旧数据头节点的指针。
Delta Storage
Delta Storage 与 Time-Travel Storage 类似,只不过只存储的是属性的修改值,并不需要存储整个 tuple 的历史版本。这样可以节省很多空间,但是在寻找版本的时候,必须重返旧版本才能得到相应版本的数据。MySQL 中采用的就是这种方式。




