
15-445 Query Plan and Optimization
15-445 地址 https://15445.courses.cs.cmu.edu/fall2021/schedule.html
Query Plan
SQL 是一种声明式语言,它只是告诉 DBMS 它想要哪些数据,但是并不会告诉 DBMS 如何获取他们。当 DBMS 接收到一个 SQL 语句,它会经历若干阶段,形成逻辑计划,然后根据逻辑计划来执行得到用户想要的数据。一般一个 SQL 语句会经过的阶段如下图所示
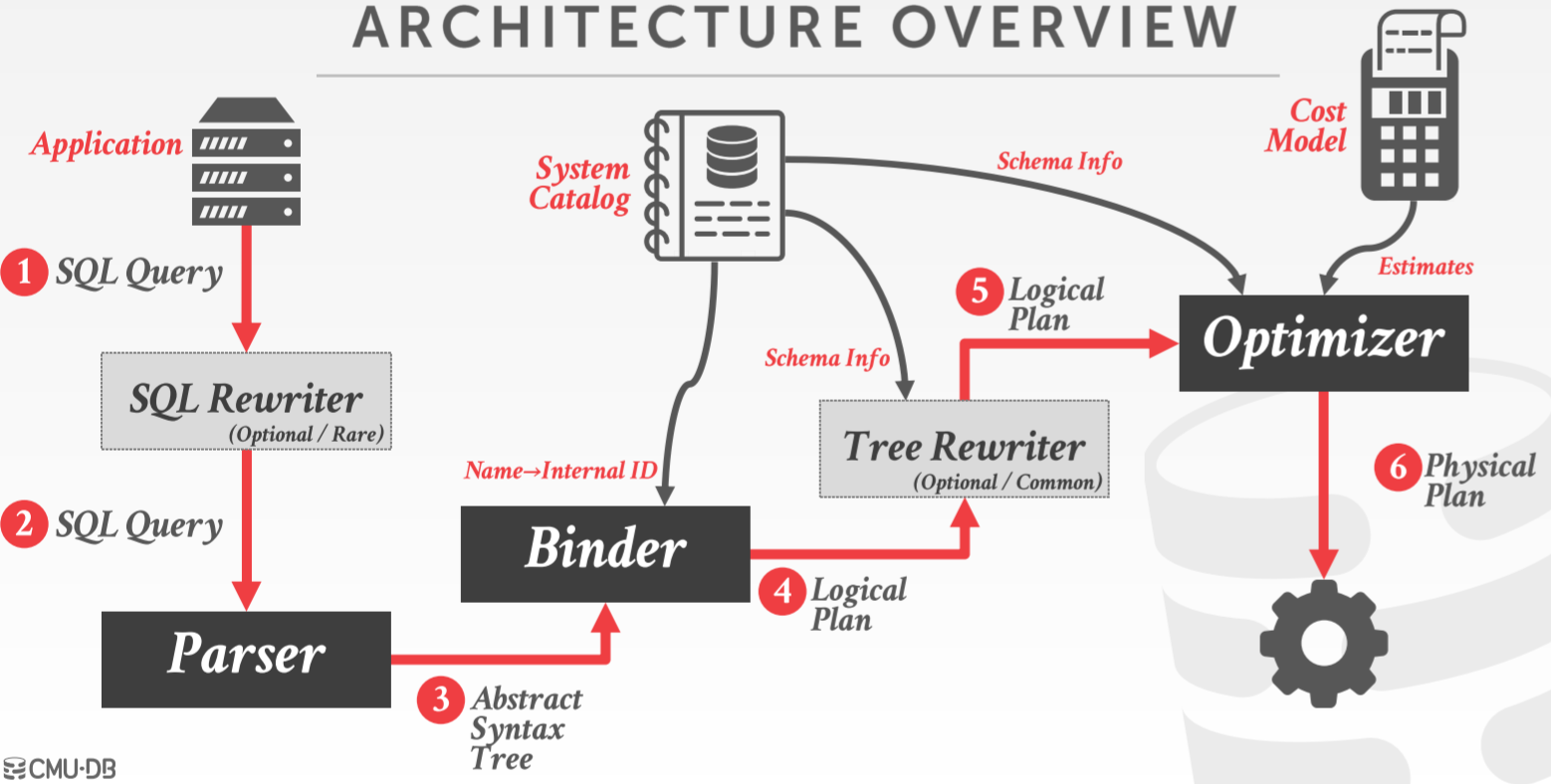
- SQL Rewriter:在该阶段,DBMS 会通过某些规则,对 SQL 进行重写,比如通过 SQL 中指定的表名,到 catalog 中查找到表,然后替换为该标识,如果没有找到就会报错。这个阶段是可选的。
- Parser:该阶段会进行词法分析、语法分析,将 SQL 语句转换为抽象语法树,然后传递给下一阶段
- Binder:该阶段会到 System Catalog 中查找相关信息,并将 SQL 查询中所引用的命名对象转换为内部的某种标识,输出逻辑计划。
- Tree Rewriter:该阶段会重写抽象语法树,通过静态规则对每个查询都进行改写,这个过程需要查询 System Catalog
- Optimizer:使用成本模型(Cost Model)找出最佳的方案。这个过程会使用到 System Catalog 中的 schema 信息和成本模型,并对成本进行估算,生成物理计划。
上面提到两个计划(逻辑计划和物理计划),其中逻辑计划是指这个查询想要做什么,比如查询 id > 2 的 tuples,但是它并不关心该如何执行这个查询。而物理计划是指 DBMS 实际该如何执行这个查询。
Query Optimization
查询优化大致有两种方法:
- 启发式/静态规则(Heuristics/Rules):如果查询中某部分满足某种条件,就会触发规则,对查询进行重写。该过程可能需要 catalog 中的信息,但是并不需要知道数据的情况
- 基于成本的搜索(Cost-based Search):枚举 SQL 的所有可能的查询方案,去除多余或愚蠢的方案,并通过某种成本模型估计方案的执行成本。该过程需要以某种方式知道数据大的情况
Heuristics/Rules
我们可以通过对关系代数进行重写,来获取等价的效果,这被称为 query rewriting
如果两个关系代数生成相同的结果,那么成这两个关系代数等价(equivalent)
谓词下推(Predicate Pushdown)
对于一个查询,我们可以提前对数据进行过滤,从而减少传递给父节点的数据,因为我们知道有些数据会在父节点被过滤,所以我们提前将父节点的条件下推到子节点。比如下面两条查询语句等价
Projection Pushdown
和 Predicate Pushdown 类似,不过是把要映射的属性下推,子操作不需要传递完整的 tuple,只需要向父操作传递需要的属性即可,这样同样大小的内存就可以存放更多的 tuples 了。比如在下面的两条语句等价
去除无用或不可能的谓词
同样我们可以山区不必要的谓词条件,比如 1 = 1,如果出现 1 = 0 这样的操作,我们也可以直接返回 false(空)
谓词合并
有时候我们可以将多个谓词条件合并为一个谓词,这样就可以减少一些额外的工作。比如范围查找 val between 1 and 100 or val between 50 and 150 可以直接合并为 val between 1 and 150。
Cost-Based Search
Cost-based Search 的宗旨就是在不执行查询的情况下,通过成本模型估算该查询中要做的工作量。其原理就是尽可能多地列出查询计划,从中选择最好佳的方案。
DBMS 通过成本预测(Plan Cost Estimation)估测执行一个查询所要做的工作量。它会通过在 catalog 中存储关于 table、attribute、index 等 统计(statistics)信息来支持这一行为。
在预测成本之前,我们需要弄清楚要预测什么成本。我们可以考察 CPU cycles、I/O 成本、缓存不命中的成本、每个操作产生的数据的大小等,但是在这些因素中,I/O 成本总是不可忽略的。
选择基数(selection cardinality) 指的是属性 A 的不同值平均出现的次数。比如一共有 10 条 tuples,属性 A 在记录中出现的值分别为为 1, 1, 2, 2, 3, 3, 4, 4, 5, 5,那么属性 A 有 5 中不同的值,则选择基数为 2()。通过选择基数,我们可以估算子操作返回的数据量。选择基数的计算公式如下:
其中 表示 tuples 的数量; 表示表中属性 A 不同值的 tuples 数量(可以理解为 DISTINCT 的结果)。
上面的计算公式可能会出乎我们的想象,因为如果数据分布不均匀,该公式得到的结果与实际相差会很大。所以上面的公式基于这样一个假设:数据是均匀分布的。
有了选择基数,我们可以算出每个条件的选择率(Selectivity)。比如要得到属性 A 为常熟 c 的 (P 表示谓词条件)。比如在我们上面举的例子中 2 的选择率 。大于 2 的选择率 。
为了继续讨论,我们还要提出两个假设,这里我们将这三个假设放在一起
-
数据是均匀分布的
-
数据之间相互独立
-
嵌套原则(Inclusion Principle):对 inner 表中的每个 tuple,outer 表中会有一个与之对应的 tuple
有了假设 2,根据概率公式,我们可以计算出更复杂属性的选择率了。比如由 可以得到 。
有了假设 3,我们可以估计 Join 操作产生结果集的大小。比如 ,如果对于 R 中的每个 tuple,S 中都有与之匹配的 tuple,那么 。如果对于 S 中的每个 tuple,R 中都有与之匹配的 tuple,那么 。那么可以得到 。
但是现实中,不可能总是满足上面三条假设的。如果出现数据倾斜,那么我们可以将热点数据单独处理。如果有些条件是相关的,那么我们对相关列进行统计,让 DBMS 将它们当作特殊案例来处理。
下面我们来介绍一下估计成本的方法
Histogram
对于要统计的数据,我们可以维护一个 Hash Table,对每中值的数据个数进行统计,在内存中形成一个直方图分布。有了这个数据的直方图,我们就可以精准地估计操作产生数据集的大小。但是如果数据很多,需要的内存是巨大的,所以我们不对每一个值进行统计,而是对区间进行统计(这样不可避免地会引入误差)。如果我们知道区间的最大值和最小值,那么我们可以将数据均匀划分为若干个区间,我们统计这个区间的数据分布情况。这种方法称之为等宽直方图(Equi-Width Histogram)。一个等宽直方图的例子如下图所示
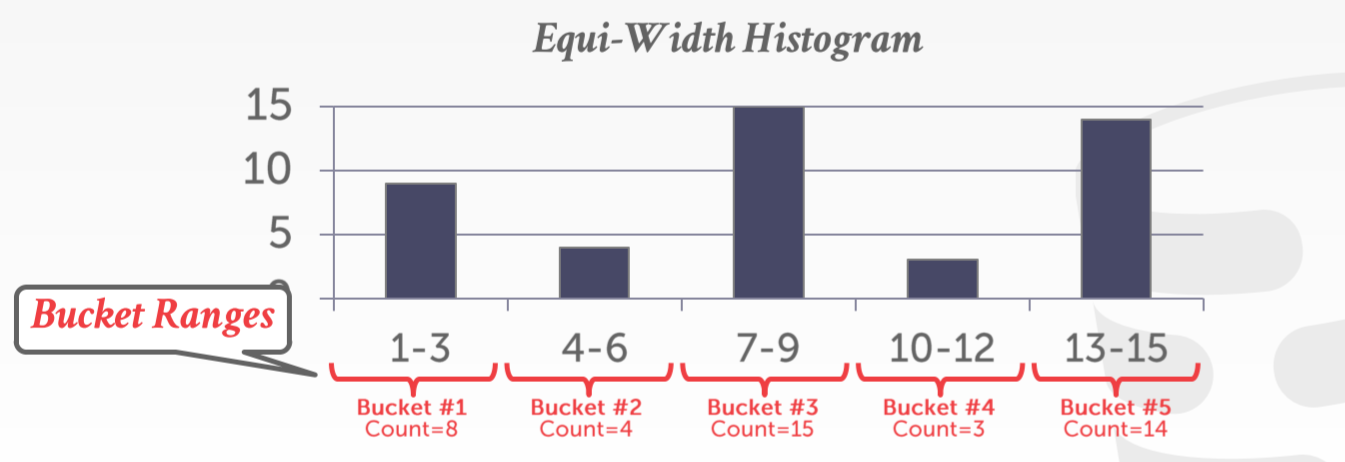
如果我们要估计得到属性值为 8 的数据量,那么我们找到第三个区间由 15 个数据,区间宽度为 3,那么我们估计 8 出现了 5 次(我们假设区间中数据是均匀分布的)。
我们还可以以其他方式划分区间,比如让每个区间的数据量都大致相等,这中方式称之为等高直方图(Equi-Depth Histogram)。
通过对区间划分,我们只需要存储很小的数据,如果数据量很大,那么我们存储的这点数据完全可以忽略不记。但是随着数据的更新,我们的统计数据可能会失效。但是这并没有关系,我们可以对这些统计数据进行更新,比如选择在负载小的晚上更新,也可以手动强制更新(有些 DBMS 提供了一些命令会强制更新,比如 MySQL 的 Analyze Table)。
Sampling
除了使用直方图的方式统计数据,我们还可以对 tuples 进行取样,用样本的数据分布估计总体的数据分布。
我们在 DBMS 中为每张表维护一张样本表,然后在表中随机选取若干 tuples 插入样本表。当查询数据时,我们在样本表中查询,用数据在样本表中的概率来统计数据在表中的数量。同样,当表更新时,我们也可以选择一个时机更新样本表。
Plan Enumeration
对查询进行重写后,DBMS 可以通过枚举不同的查询计划,并从中选出一个最佳的方案执行。下面我们来介绍一下枚举的方法
Single Relation
对于只有一个关系的查询,我们可以很简单地实现,比如顺序扫描检查 tuple 是否匹配;也可以使用索引扫描加快速度。查询优化器需要做的就是从不同的索引中选出最好的,这时索引的选择性就会起到很大的作用。
Multiple Relations
对于多关系的查询就复杂很多,因为将多个关系进行排列组合,可以得到很多中情况,要想从中找到最优的情况还是挺难的。对于一个有 n 个关系的查询,一共有卡特兰数中情况,其复杂度时 级别的,所以这里我们只考虑 left-deep join 的情况,这样能将复杂度讲到 2^n 级别。关于 left-join tree,可以参考这里
有了操作的关系的不同情况,我们还需要考察每一步采用怎样的方式执行才能让成本最低(顺序扫描,排序还是 Hash),我们可以用动态规划的方式从这么多情况中找到一个最优解。



