
15-445 Query Execution
15-445 地址 https://15445.courses.cs.cmu.edu/fall2021/schedule.html
DBMS 将 SQL 转化为查询计划,而查询计划会将 operators 组织成一颗树,数据可以从根流向叶子节点,称为 Top-To-Bottom,也可以从叶子节点向上传递到根节点,称为 Top-To-Bottom。本文的重点是 Top-To-Bottom
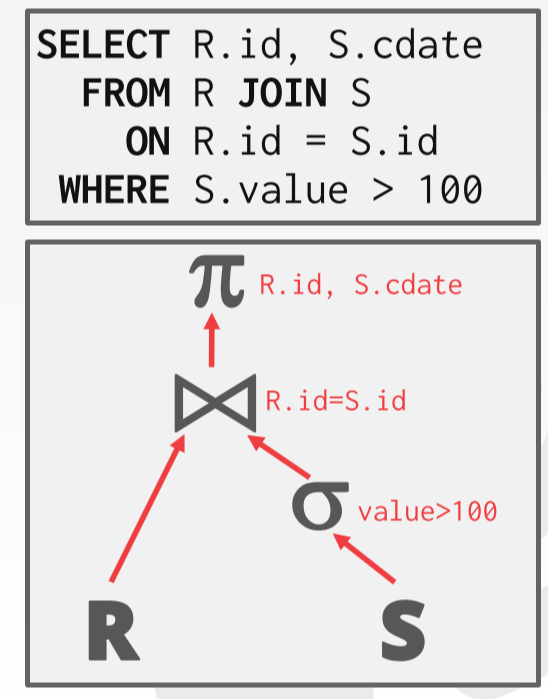
处理模型
DBMS 的处理模型定义了 DBMS 应该如何执行一个查询计划,下面会介绍三种可用的模型
- Iterator Model
- Materialization Model
- Vectorization Model
在处理模型中,每个 operator 都会定义一个next函数供父节点调用,这个函数会返回父节点需要处理的 tuples,而我们要介绍的三种模型都是只是对next函数进行了改造
Iterator Model
迭代(Iterator)模型要求一次返回一个完整的 tuple,即父节点调用 next 从子节点处获取 tuple,子节点将一个完整的 tuple 返回给父节点。迭代模型的伪代码如下图所示
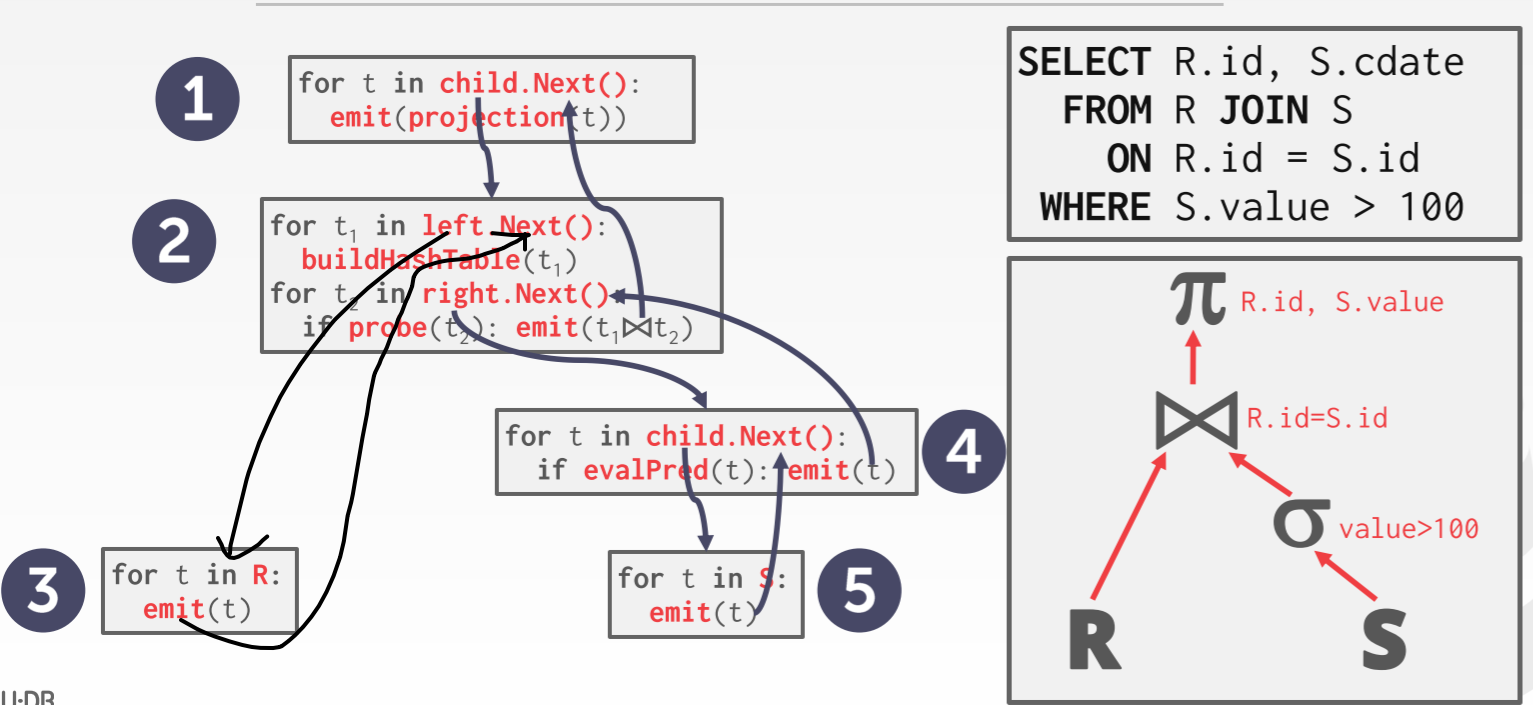
在上图中,根节点调用子节点(Join 操作)的 Next,Join 操作右调用左孩子的 Next 获取 tuple,并用我们之前介绍的 Hash Join 的方法构建 Hash Table。然后调用左孩子的 Next,并检测 tuple 是否匹配,如果匹配,就从将 tuple 向上传递会父节点。通过不断迭代执行,最终会产生所有的输出结果。
Iterator Model 是最基本的模型,基本上所有的 DBMS 都支持该模型。这种模型还被称为 Pipeline Model,因为每个操作计算都是相互独立的,而且数据以行的形式从叶子节点流向根节点。但是如果遇到 Order By、子查询等需要获取更多信息的操作(pipeline breaker)时,该模型的效率会很低(因为只能一个一个地传递,在此期间父节点被阻塞)。
Materialization Model
Materialization Model 的思想是一次性把所有值传递给父节点,这里并不要求传递完整的 tuple。子节点会先把值存在一个缓存中,等收集到所有值后在传递给父节点。
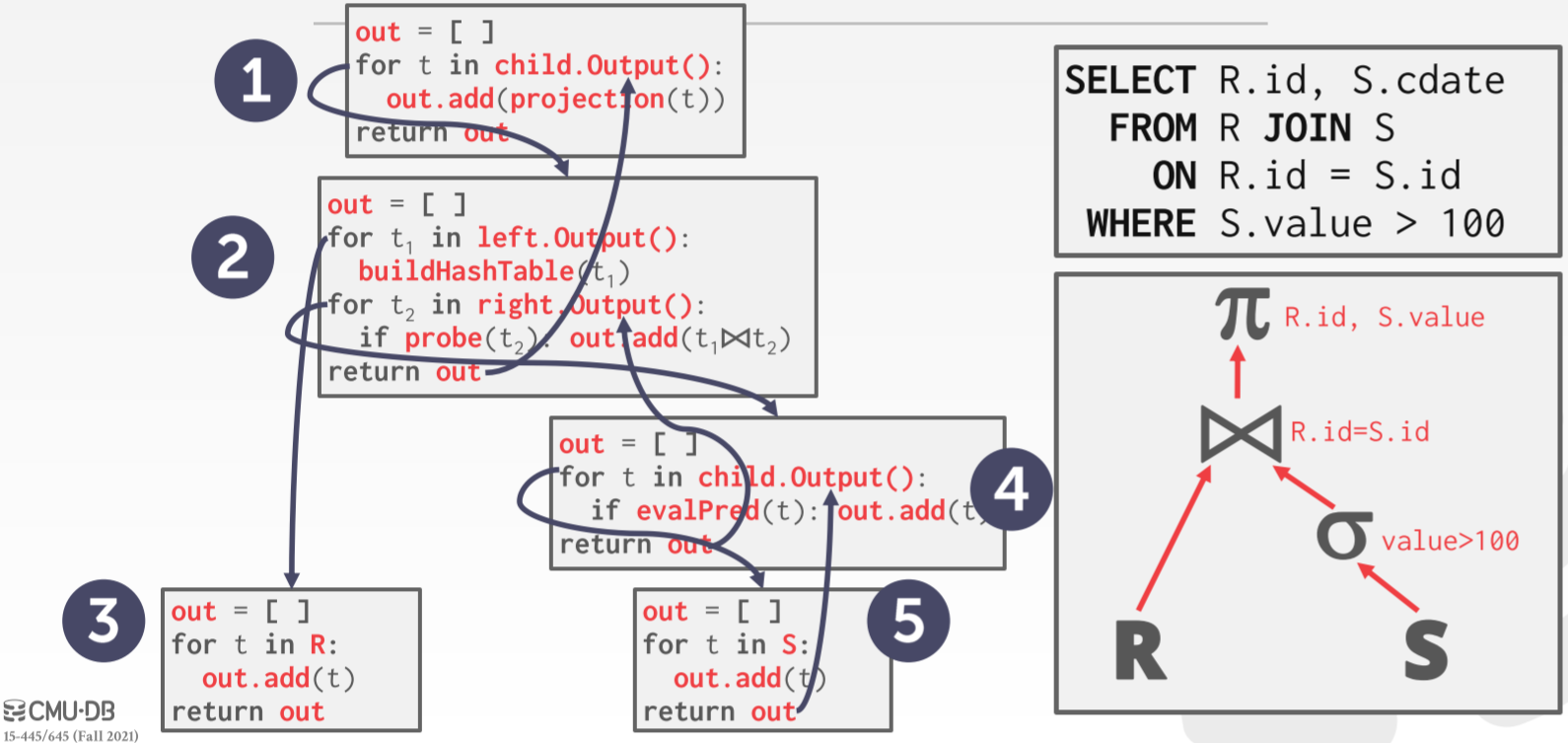
如果遇到 Limit 操作,该模型的效果并不是很好,所以我们需要维护某些信息,让子节点知道要传递会父节点数据的数量。
这种模型更适合 OLTP 负载,但是不适合 OLAP。因为在 OLAP 中需要读取大量的数据,而在该模型中需要将数据存储在内存中,这会占用大量的内存。
Vectorized/Batch Model
Vectorized Model 更像是上面两种模型的这种,它并不是一个一个地处理,也不是一次性传递全部数据,而是一次传递一批数据。同样,子节点会将数据缓存到内存中,等数据达到一定量后发送给父节点。
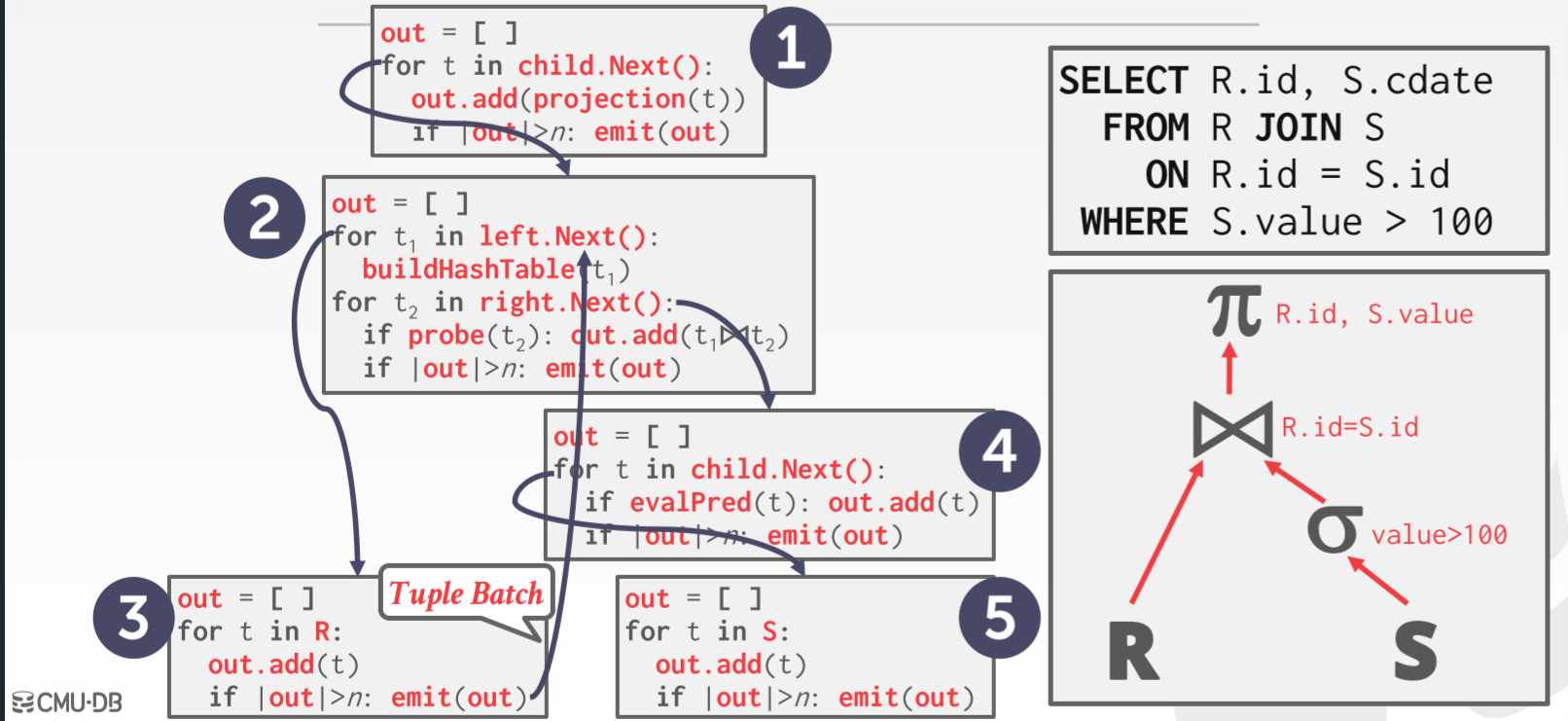
这种模型比较适合 OLAP,因为子节点每次都只缓存部分数据,并不会占用太多地内存。
访问方法
访问方法(Access Method)指的是 DBMS 访问表中数据的方法,比如顺序扫描、索引扫描
我们可以用下面的方法进行优化扫描:
- 预取(prefetch),使用两个 BufferPool,当 DBMS 在处理操作时,提前将数据加载到另一个 BufferPool
- BufferPool Bypass,使用一个小 BufferPool,对查询的结果进行缓存
- Parallelization,并行执行
- Zone Map,在页面计算一些元信息(如page中最大最小值),以此来判断是否需要扫描该页。
- Late Materialization,子节点向上传递 offset,而不数据,需要时才从pages 中取数据
- Heap Clustering,使用选择性更高的索引



