
6.830 Lab1
6.830 Lab1
6.830 的 lab 的目标是实现一个简单的数据库管理系统,只提供了 DMBS 的基础功能,包括对数据的存储进行描述和解释,应用查询条件来找到匹配的 tuples,提供查询 tuples 的访问方法等。
Tuple Layout
Exercise 1:完成 Tuple 和 TupleDesc 的相关信息。
SimpleDB 采用的是行存储的形式,即所有属性都通过数组组织到一起。
TupleDesc 这个类用于描述 tuple 的 schema,里面包含了一个 tuple 应该拥有哪些属性,以及属性的类型信息。而 Tuple 存储着记录的实际内容,即 tuple 中的属性值。由此我们可以写出 TupleDesc 和 Tuple 应有的属性
1 | public class TupleDesc implements Serializable { |
1 | public class Tuple implements Serializable { |
Exercise2:实现 Catalog
Catalog 存储了表的一些元信息,在以后的操作中可以提供相应的信息(如表、索引、视图、权限、统计数据等)。在 SimpleDB 中的实现很简单,只提供了几个必要的属性。
Page Layout
Exercise3:实现 BufferPool#getPage()
Buffer Pool 是我们用来管理 pages 的一块缓存池。当我们需要一个 page 时,我们从磁盘上加载到 Buffer Pool,如果 Buffer Pool 满了,我们需要淘汰一个 page。在 Buffer Pool 中,我们有一个页表,用来建立磁盘 Page 到 Buffer Pool Page 的映射,以方便我们管理 pages。
1 | public Page getPage(TransactionId tid, PageId pid) { |
Exercise4:实现 HeapPageId, HeapPage, RecordId
在 SimpleDB 中,我们使用 Tuple-oriented 的方式组织 page 中的数据,Tuple-oriented 的大致结构如下图
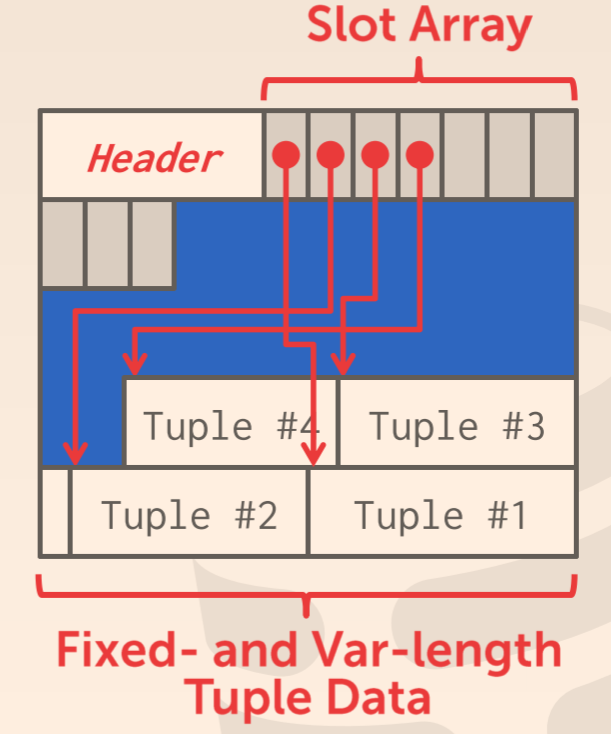
因此我们需要一个 Header 来记录页面的相关信息,需要一个 slots 数组,来定位到页面中的 tuples。
1 | public class HeapPage implements Page { |
HeapPageId 是用来定位 Page 的,而 RecordId 是用来定位 tuple 的,因此只需要定义一个能够唯一标识 Page 或 Tuple 的信息即可。
File Layout
Exercise5:实现 HeapFile,
SimpleDB 在实现上与 Page Directory 比较像,Page Directory 的大致思想如下图所示
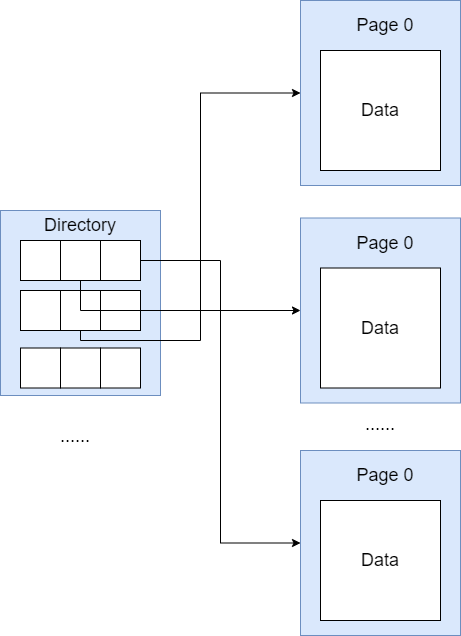
但是 SimpleDB 的实现方式与 Page Directory 有所不同,它将整张表的数据都存储到一个文件中,所以可以省去目录页中的一些信息。因为一个 page 的大小是固定的,我们只需要通过页号就能够计算出页面在 HeapFile 中的偏移,然后就可以将页面读取出来了。可以理解为因为我们不需要目录页就可以找到 page,所以我们就将目录页给省去了,但是如果我们想把 pages 放在不同的 files 中,目录页还是很有必要的。下面是从 HeapFile 中读取页面的伪代码
1 | public Page readPage(PageId pid) { |
完成了上面的 exercises,我们可以开始写一个简单的顺序查询了。exercise6 就是实现一个 SeqScan,来实现对 tuples 的顺序扫描。
在实现的时候,要主要顺序扫描所有pages 中的所有 tuples。因为有些 pages 可能没放满,也有可能有些 pages 压根就没有 tuples,所以在实现迭代的过程中要考虑到这些情况。




