
15-445 Join & Aggregations
15-445 地址 https://15445.courses.cs.cmu.edu/fall2021/schedule.html
Aggregations
Aggregations 的工作就是将多个属性的值根据某种策略聚合为一个值,比如 COUNT, SUM, AVG 等操作。
Aggregations 有两种实现方法,一种是 Sorting,一种是 Hashing
Sorting
这里介绍的是基于磁盘的数据库,所以我们无法假设需要排序的数据都可以放入内存。因此我们需要对数据进行外部排序,在课程中介绍了 External Merge Sort。
假设我们有 N 个待排序的 pages,Buffer Pool 可以容纳 B 个 pages。外部归并排序首先会将待排序的数据集划分为 个部分,每一部分称为一个 run。在第一阶段,将 B 个 pages 放入 Buffer Pool,进行内部排序,然后写回磁盘。第一阶段完成后,每个 page 中的数据都是有序的,接下来进行第二阶段。第二阶段会将有序的 B - 1 个 page 加载进 Buffer Page,然后利用归并排序的归并过程,将 pages 合并到一个 page 中并写入磁盘。重复第二阶段的过程,直到所有数据变为有序。大致过程如下图所示
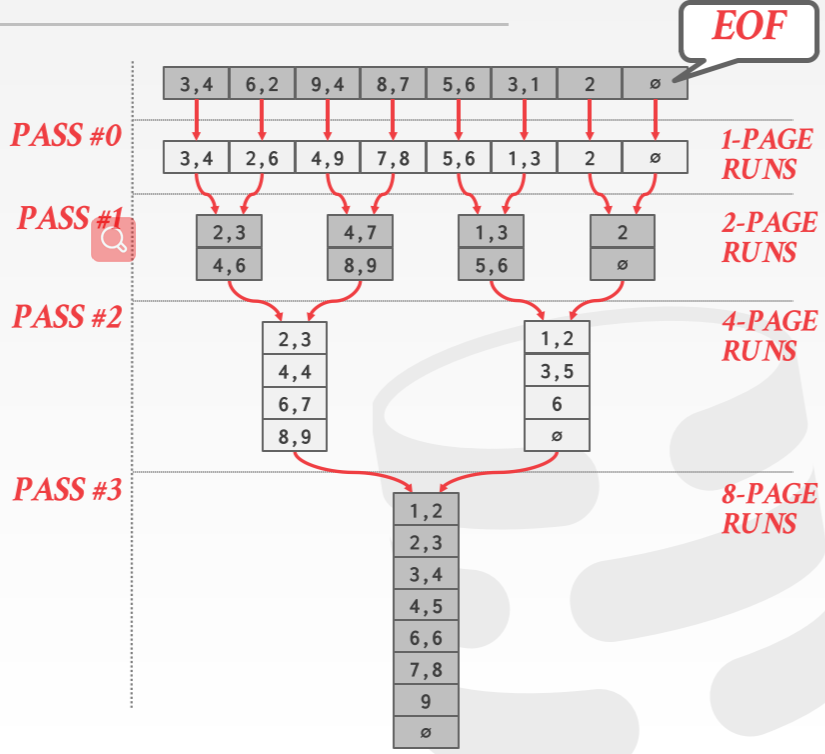
假设 N = 108,B = 5,
- 在 pass0,将 108 个 pages 加载得到 Buffer Pool 中各自排序并将其划分为 22()个 runs,每个 run 有 5 个 pages(最后一个只有 3 个 pages)。
- 接着在 pass 1,每次将 4 个已有序的 pages 放入 Buffer Pool 中,合并到另外一个 page 中(边合并编写如磁盘),得到 6() 个部分,每部分有 20 个 pages(最后一个部分只有 8 个 pages)
- 在 pass2,重复 pass1 的过程,得到 2() 个部分,每部分有 80 个 pages(最后一个部分只有 28 个 pages)
按照上述方法,一共需要 个 pass,因为每一个 pass 都会将未排序 runs 减半。同时每个 pass 还需要 2N 次 I/O 操作(一次读,一次写)。
因为不管 Buffer Pool 有多大,I/O 操作的成本都不会改变,所以如何减少 I/O 等待事件就成为了优化的关键。我们可以使用预取(Prefetch)的方法来加速排序过程。其思想是当系统在处理当前 run 的时候,我们提前将下一个要处理的 run 加载进另一个 Buffer Pool,一次来减少 I/O 请求的等待时间。
除了将数据集进行排序,我们还可以利用现有的聚簇索引有序的特点来加快查询的速度。如果要排序的 key 刚好是聚簇索引的 key,那么我们可以直接从最左边的叶子节点开始遍历。但是如果是非聚簇索引,除非叶子节点刚好包括我们需要的数据,否则这并不是一个好方法(因为页面中的记录并不是按照排序的 key 排序的,所以回表时进行的是随机 I/O)
将数据排好序了,做 MAX, MIN,DISTINCT 这样的操作就很方便,如果条件有 ORDERBY,那这种 Sorting 的方法的效果一般都比较好。
Hashing
使用 Hashing 处理 Aggregations 操作时,大致分为两个阶段
- 第一个阶段:对 key 进行 hash,这样拥有相同 hash 的 key 会放入相同的区域。然后写入磁盘
- 第二个阶段:对每一个区域,在内存中构建新的哈希表,然后进行相应的处理
Join
在执行 Join 时,通常会将一个操作的输出作为下一个操作的输入,比如 A join B 会将 A、B的输出作为输入,传递到 Join 操作中。为了更好地分析 Join,我们可以将关系代数转换为一个有向图或树。
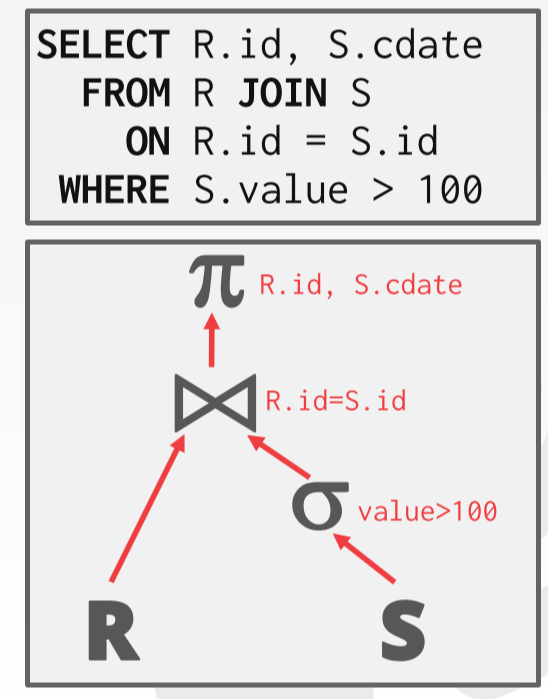
将输出传递给下一个操作时有两种选择。一种是将所有属性传递给下一个操作,这种方法在得到最终结果后不需要进行回表,但是如果属性很多,占用内存很大。另一种方法是值传递最少量的属性,即值传递 join keys 和需要匹配的条件。得到最终结果后回表找到其他属性。
Nested Loop Join
Nested Loop Join 的基本思想是对于一个表中的 tuple,遍历另外一个表,检测是否匹配。伪代码如下:
1 | foreach tuple r∈R: // outer |
假设 outer 表有 M 个 pages,共有 m 个 tuples,inner 表有 N 个 pages,共有 n 条 tuples,那么执行所需的 I/O Cost 为 。从 I/O 成本的公式可以看出,将小表作为 outer 表可以减少 I/O 成本。
在计算机的层次结构中,数据都是以块(block)为单位读取的,而在数据库中,我们以 page 为单位读取数据。为了最大化一次 I/O 所做的工作量,我们也可以以 block 为单位进行 Join操作。其基本思想为:对于 outer table 中的每个 block 中的 tuple,每次从 inner table 中取出一个 block,遍历该 block,检查是否匹配。伪代码如下
1 | foreach block Br∈R: |
假设 Buffer Pool 可以存放 B 个 pages,那么对于使用 block 优化后的 Nest Loop Join,需要的 I/O Cost 减少到了
如果对于要 Join 的 key,我们已经又有了索引,那么我们可以利用该索引来减少 I/O。因为索引中的记录是顺序存放的,所以在遍历索引时,我们进行的是顺序 I/O,这比随机 I/O 要快很多。而且我们也可以使用预取(Prefetch)的方法来减少 I/O 等待的时间。使用索引优化的伪代码如下
1 | foreach tuple r∈R: |
Sort-Merge Join
对于 Join 操作,如果得到的数据集是有序的,那么可以加速 Join 所需的时间。
Sort-Merge Join 分为两个阶段。第一个阶段对表中的 tuple 按照 join keys 进行排序。第二个阶段进行 merge,在 merge 的过程中匹配条件是否匹配
1 | sort R,S on join keys |
使用 Sort-Merge Join 不需要回溯 outer join,但是 outer 中如果出现值相等的情况,inner 表中的指针可能需要回溯。为了解决这个问题,我们可以维护一个指针,记录上一条记录第一次匹配的位置,当需要回溯是,inner 的当前指针回溯到上一条记录第一次匹配的位置。
使用该方法对两个表 R 和 S 的 Sort 的 I/O 成本分别为为 和 ,Merge 的 I/O 成本为 (M + N),总成本为这三者的总和
Hash Join
Hash Join 的思想是相同 key 会被 hash 到相同的分区,利用该思想,我们可以很快地找到匹配的 tuples。Hash Join 分为两个阶段:Build 和 Probe
- Build 阶段,对 outer table 扫描并将 key hash 到 hash table中。
- Probe 阶段,对 inner table 扫描并对 key 进行 hash,得到相应的分区,并到该分区中寻找是否有匹配的 tuple。
1 | build hash table HTR for R |
使用 Hash Join,我们一次只需要关心一个分区的 tuples,这样减少了内存的负担。我们还可以使用 布隆过滤器在不对分区进行扫描的情况下知道一个 key 是否在 hash table 中。在通过网络传输查询时很有效,可以先将 Bloom Filter 传过去。
如果数据分布十分不均匀,一个分区中可能有过多的数据,那么我们就需要将数据写回到磁盘。为了减少这种情况的发生,我们可以使用 Grace Hash Join。
在 Grace Hash Join 中,我们对 outer 和 inner 表分别构建 Hash Table。然后对匹配的分区进行 Nested-Loop Join。当发生数据倾斜时,我们可以将数据过多分区中的数据再次 Hash 到另一个 Hash table 中。扫描时,如果先用第一个 hash 函数得到相应分区,如果该分区数据没有溢出,那么扫描该分区。如果该分区数据溢出了,那么我们可以使用第二个 hash 函数,找到相应的分区。

假设 outer 表有 M 个 pages,inner 表有 N 个 pages,那么 Build 阶段构建 Hash Table 所需的 I/O Cost 为 。Probe 阶段所需的 I/O Cost 为 。因此总的 I/O Cost 为




